ES Module
单独记录一下ES Module,听得太多用的也多,但是一直没深刻的认识一下它。
同样的节奏先Google找是否有大佬写这方面的文章。
幸运的是被我找到了Lin Clark(之前我学习浏览器方面的知识就是读的她的文章)写的,很喜欢她的文章,讲的很生动和具体。
开始
来来来,搬运一下这一篇ES modules: A cartoon deep-dive。
模块如何提供帮助?
模块为您提供了更好的方式来组织这些变量和函数。使用模块,您可以将有意义的变量和函数组合在一起。
这会将这些函数和变量放入模块范围。模块作用域可用于在模块中的功能之间共享变量。
但是与函数作用域不同,模块作用域具有一种使其变量也可用于其他模块的方式。他们可以明确地说出模块中的哪些变量,类或函数应该可用。
当其他模块可以使用某些东西时,这称为导出。导出后,其他模块可以明确地说它们依赖于该变量,类或函数。
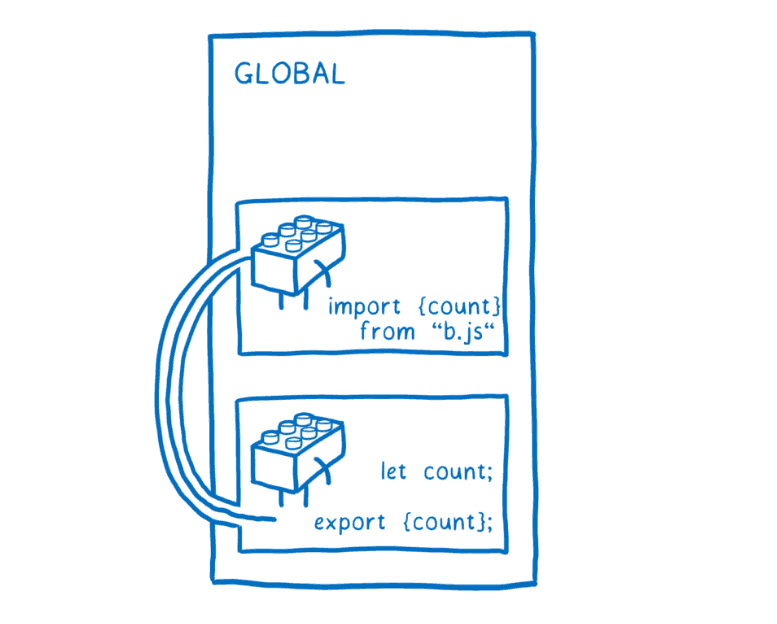
因为这是一种明确的关系,所以您可以知道如果删除另一个模块,哪个模块将中断。
一旦能够在模块之间导出和导入变量,就可以更轻松地将代码分解为可以相互独立工作的小块。然后,您可以组合并重组这些块(类似于积木),以从同一组模块创建所有不同种类的应用程序。
ES模块如何工作
在使用模块进行开发时,您将建立一个依赖关系图。不同依赖项之间的连接来自您使用的任何导入语句。
这些导入语句是浏览器或Node如何确切知道其需要加载哪些代码的方式。您给它一个文件,以用作图形的入口点。从那里开始,它紧随任何import语句以查找其余代码。

但是文件本身不是浏览器可以使用的东西。它需要解析所有这些文件,以将它们转换为称为模块记录的数据结构。这样,它实际上知道文件中正在发生什么。

之后,需要将模块记录转换为模块实例。实例结合了两件事:代码和状态。
该代码基本上是一组指令。这就像如何做某食物的食谱。但是就其本身而言,您不能使用该代码执行任何操作。您需要原材料才能与这些代码一起使用。
什么是状态?就像做食物的原材料。状态是变量在任何时间点的实际值。当然,这些变量只是内存中保存值的空间的昵称。
因此,模块实例将代码(指令列表)与状态(所有变量的值)组合在一起。

我们需要的是每个模块的模块实例。模块加载的过程将从此入口点文件变为具有模块实例的完整图。
对于ES模块,这分为三个步骤。
- 构造—查找,下载所有文件并将其解析为模块记录。
- 实例化—查找内存中的空间以放置所有导出的值(但尚未用值填充它们)。然后使导出和导入都指向内存中的那些空间的位置(地址)。这称为链接(引用)。
- 求值—运行代码以将变量的实际值填写在对应的内存空间。

人们谈论ES模块是异步的。您可以将其视为异步的,因为工作分为三个不同的阶段(加载,实例化和评估),并且这些阶段可以分别完成。
这意味着规范确实引入了CommonJS中不存在的一种异步。我将在后面解释,但是在CommonJS中,模块及其下面的依赖项一次全部被加载,实例化和求值,而中间没有任何中断。
但是,步骤本身不一定是异步的。它们可以以同步方式完成。这取决于正在执行的加载。这是因为并非所有内容都由ES模块规范控制。实际上有两部分工作,分别由不同的规范涵盖。
在ES模块规范说,你应该如何解析文件到模块的记录,你应该如何实例化和评估模块。但是,它并没有说明如何首先获取文件。
加载程序将获取文件。加载程序在其他规范中指定。对于浏览器,该规范是HTML规范。但是您可以根据所使用的平台使用不同的装载程序。

加载程序还精确控制模块的加载方式。它调用ES模块的方法- ParseModule,Module.Instantiate和Module.Evaluate。有点像操纵JS引擎的字符串的p。

现在,让我们详细介绍每个步骤。
构建
在构建阶段,每个模块发生三件事。
- 找出从哪里下载包含模块的文件
- 提取文件(通过从URL下载文件或从文件系统加载文件)
- 将文件解析为模块记录
查找并获取文件
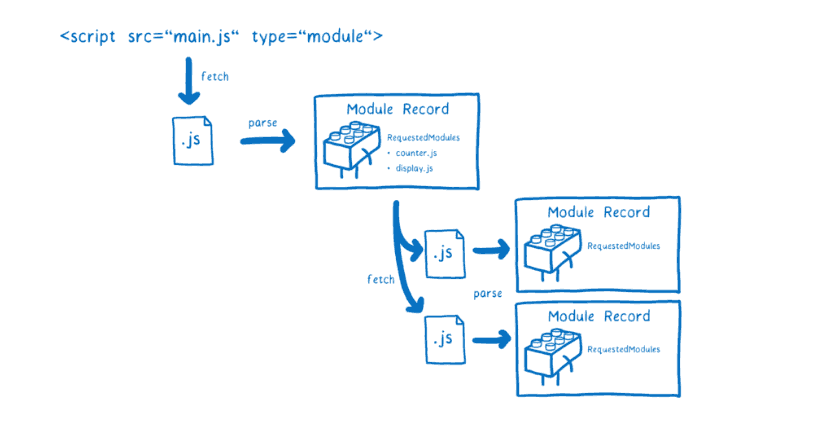
加载程序将负责查找文件并下载。首先,它需要找到入口点文件。在HTML中,您可以通过脚本标记告诉加载程序在哪里找到它。

但是,如何找到下一组模块- main.js直接依赖的模块呢?
这就是导入语句的来源。导入语句的一部分称为模块说明符。它告诉加载程序可以在哪里找到每个下一个模块。

有关模块说明符的一件事:在浏览器和Node之间有时需要对它们进行不同的处理。每个主机都有自己的解释模块说明符字符串的方式。为此,它使用一种称为模块解析算法的模块,该算法在平台之间有所不同。当前,某些可在Node中工作的模块说明符在浏览器中将无法工作,但仍在进行修复。
在此问题修复之前,浏览器仅接受URL作为模块说明符。他们将从该URL加载模块文件。但这不会同时出现在整个图表上。在解析文件之前,您不知道模块需要获取哪些依赖项,并且在获取文件之前无法解析文件。
这意味着我们必须逐层遍历该树,解析一个文件,然后找出其依赖项,然后查找并加载这些依赖项。
如果主线程要等待这些文件中的每一个下载,则许多其他任务将堆积在其队列中。
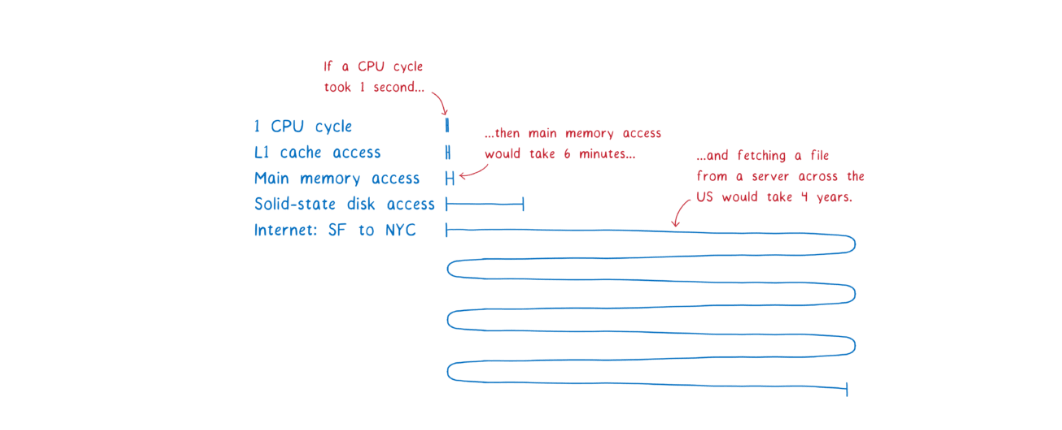
这样阻塞主线程会使使用模块的应用程序使用起来太慢。这是ES模块规范将算法分为多个阶段的原因之一。将构造分为自己的阶段,使浏览器可以在开始实例化的同步工作之前获取文件并增强对模块图的理解。
这种方法(算法分为多个阶段)是ES模块和CommonJS模块之间的主要区别之一。
CommonJS可以做不同的事情,因为从文件系统加载文件比通过Internet下载花费的时间少得多。这意味着Node可以在加载文件时阻止主线程。并且由于文件已经加载,因此仅实例化和求值(在CommonJS中不是单独的阶段)是有意义的。这也意味着在返回模块实例之前,您要遍历整棵树,加载,实例化和评估任何依赖项。
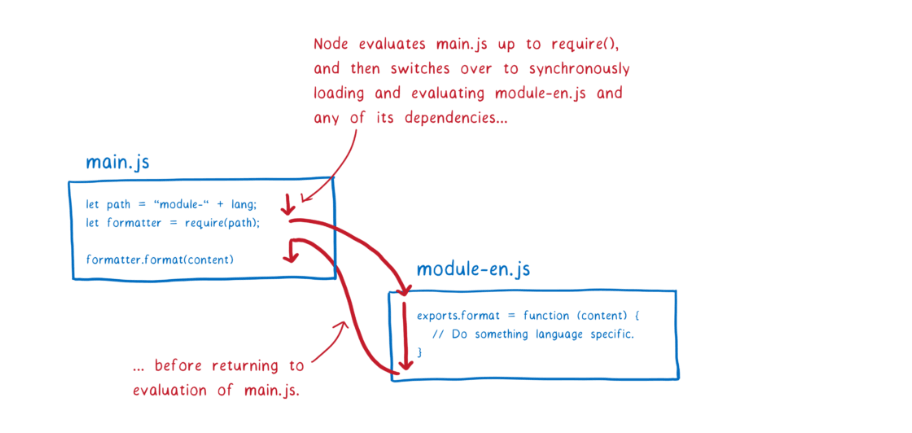
CommonJS方法有一些含义,我将在后面详细解释。但是,这意味着一件事,就是在带有CommonJS模块的Node中,可以在模块说明符中使用变量。require在寻找下一个模块之前,您正在执行该模块中的所有代码(直到语句)。这意味着当您进行模块解析时,变量将具有一个值。
但是,使用ES模块,您可以在进行任何计算(求值)之前预先建立整个模块图。这意味着您不能在模块说明符中包含变量,因为这些变量尚无值。

但是有时将变量用于模块路径确实很有用。例如,您可能想根据代码在做什么或在什么环境中运行来切换加载的模块。
为了使ES模块成为可能,有一个建议叫做动态导入。有了它,您可以使用类似的导入语句import(${path}/foo.js)。
动态导入的工作原理是,任何使用import()来导入的文件,都会作为一个入口文件从而创建一棵单独的依赖树,被单独处理。
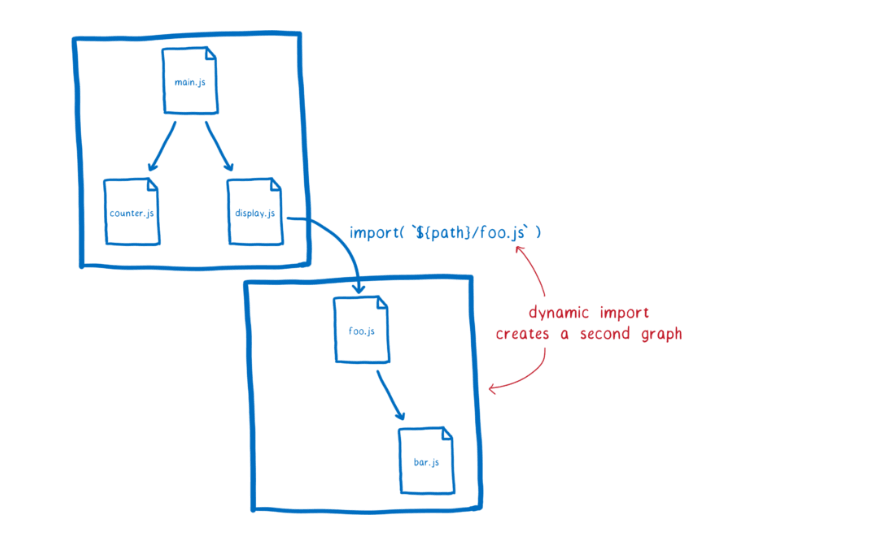
但是要注意一件事–这两棵树中的任何模块都将共享一个模块实例。这是因为加载程序会缓存模块实例。对于特定全局范围内的每个模块,将只有一个模块实例。
这意味着浏览器的工作量更少。例如,这意味着即使多个模块依赖该模块文件,该模块文件也只会被提取一次。(这是缓存模块的一个原因。我们将在评估部分中看到另一个原因。)
加载程序使用称为模块映射的内容来管理此缓存。每个全局变量在单独的模块图中跟踪其模块。
当加载程序获取一个URL时,它将把该URL放入模块映射中,并记下它当前正在获取文件。然后它将发出请求并继续以开始获取下一个文件。
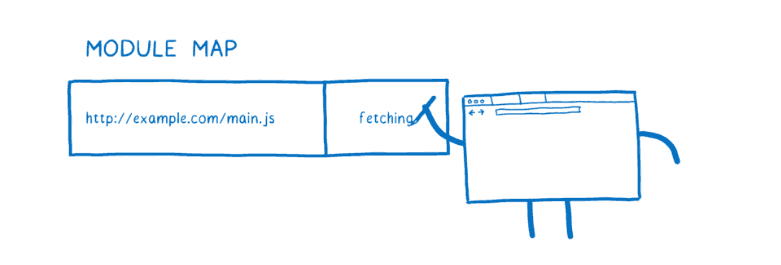
如果另一个模块依赖于同一文件会怎样?加载程序将在模块映射中查找每个URL。如果在其中看到fetching,它将继续前进到下一个URL。
但是模块图不仅跟踪正在获取的文件。模块映射还充当模块的缓存,如下所示。
解析
现在我们已经获取了该文件,我们需要将其解析为模块记录。这有助于浏览器了解模块的不同部分。

创建模块记录后,将其放置在模块映射中。这意味着无论何时从此处请求,加载程序都可以将其从该映射中拉出。

解析有一个细节看似微不足道,但实际上有很大的含义。所有模块都像严格模式来解析的。也还有其他的小细节,比如,关键字 await 在模块的最顶层是保留字, this 的值为 undefinded。
这种不同的解析方式称为“解析目标”。如果您解析相同的文件但使用不同的目标,那么最终将得到不同的结果。因此,在开始解析之前就需要知道要解析的文件类型,不管是否是模块。
在浏览器中,这非常简单。您只需放入type="module"script标签。这告诉浏览器应将此文件解析为模块。并且由于只能导入模块,因此浏览器知道任何导入也是模块。

但是在Node中,您不使用HTML标记,因此无法选择使用type属性。社区尝试解决此问题的一种方法是使用 .mjs扩展。使用该扩展名告诉Node,“此文件是一个模块”。您会看到人们将其视为解析目标的信号。目前讨论仍在进行中,因此尚不清楚Node社区最终决定使用什么信号。
无论哪种方式,加载程序都将确定是否将文件解析为模块。如果它是一个模块并且有imports,它将重新开始该过程,直到提取并解析了所有文件。
在加载过程的最后,您已经从只有一个入口点文件变成了拥有许多模块记录。

下一步是实例化此模块并将所有实例连接在一起。
实例化
就像我之前提到的,实例化是将代码与状态结合在一起。该状态存在于内存中,因此实例化步骤就是将所有状态链接到内存。
首先,JS引擎创建一个模块环境记录(Module Environment Record)。它是管理所有模块记录的变量。然后,它会在内存中找到所有export对应的的地址。模块环境记录将跟踪内存中与每个export相关联的地址。
内存中的这些地址对应的空间尚无法获取其值。只有在运行之后,它们的实际值才会被填写。需要注意的一点是:在此阶段中将初始化所有导出的函数声明。这将使后面的执行阶段变得更加容易。
为了实例化模块关系图,引擎会采用深度优先的后序遍历方式。这意味着它将到达关系图的最底部(底部不依赖于其他任何东西),并设置其导出。
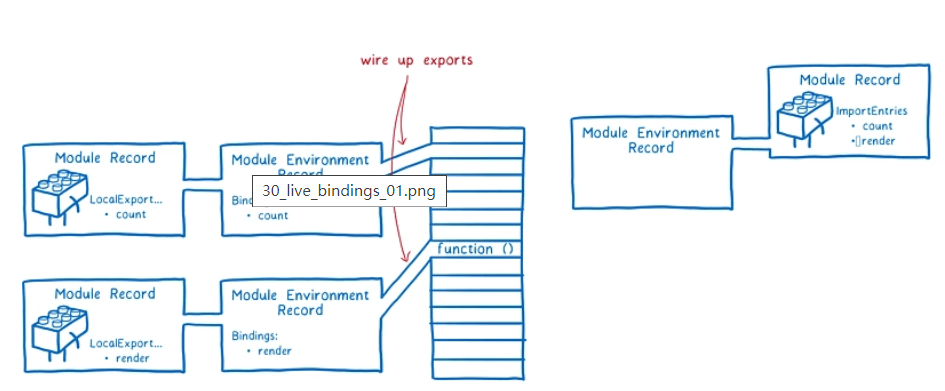
最终,引擎会把模块下的所有依赖导出连接到当前模块。接着回到上一层把模块的导入连接起来。
请注意,导出和导入均指向内存中的同一位置。
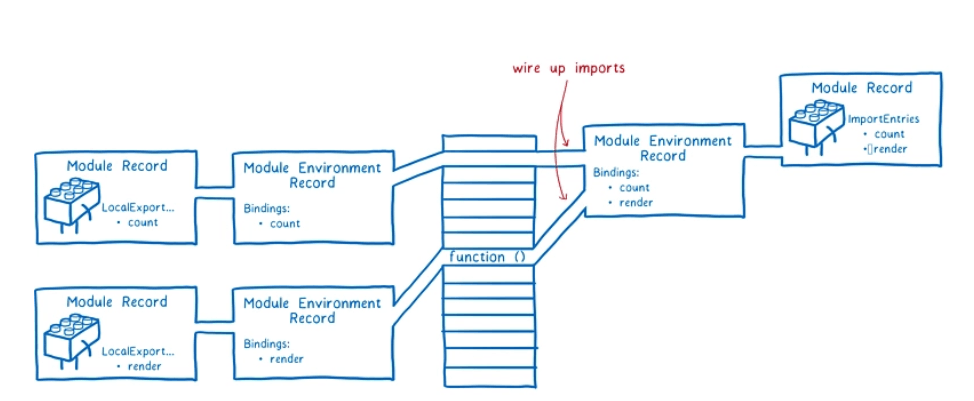
这不同于CommonJS模块。在CommonJS中,整个导出对象在导出时被复制。这意味着导出的任何值(如数字)都是副本,所以在CommonJS如果导出模块以后更改了该值,则导入模块将看不到该更改。
这意味着,如果导出模块以后更改了该值,则导入模块将看不到该更改。
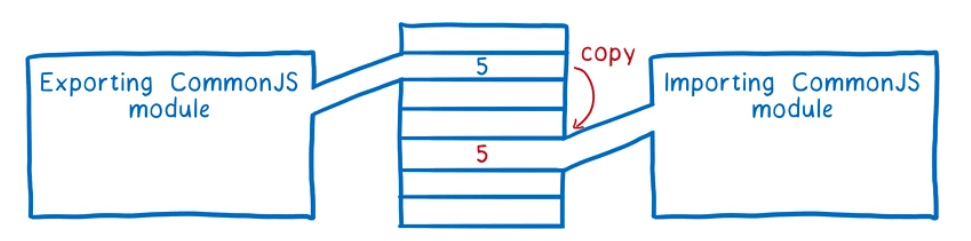
相反,ES模块使用实时绑定(Live Binding)。两个模块都指向内存中的相同位置(引用)。这意味着,当导出模块更改值时,该更改将显示在导入模块中。
导出值的模块可以随时更改这些值,但是导入模块不能更改其导入的值,因为是导入的是只读引用。不过如果模块导入了一个对象,则它可以更改该对象上的属性值。
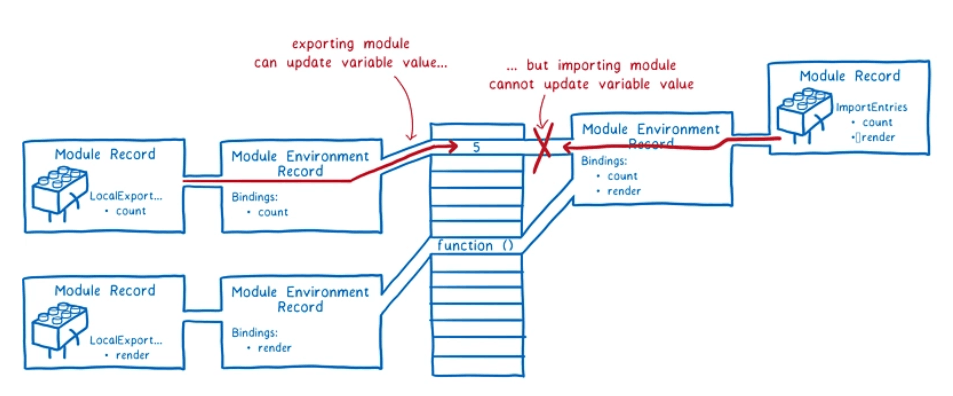
之所以ESM采用实时绑定,是因为可以在不运行任何代码的情况下链接到所有模块。这有助于解决循环依赖的问题,在后面的运行(evaluation)阶段会细说。
OK,当实例化结束时,我们得到了所有模块实例,并知道了已完成链接的导出/导入变量的内存地址。
现在我们可以开始评估代码,并使用它们的值填充这些内存位置。
运行
最后一步是往解析阶段获取的内存地址所在的空间里填充值。JS 引擎通过运行顶层代码(函数外的代码)来完成填充。
除了填充值以外,运行代码还可能引发副作用。例如,一个模块可能会请求服务器。

因为这些潜在副作用的存在,所以模块代码只能运行一次。
前面我们看到,实例化阶段中发生的链接过程可以多次进行,并且每次的结果都一样。但是,如果运行阶段进行多次的话,则可能会每次都得到不一样的结果。
这正是为什么需要有模块映射的原因之一。模块映射通过规范URL,缓存模块,因此每个模块只有一个模块记录。这样可以确保每个模块仅执行一次。与实例化一样,这是深度优先的后遍历。
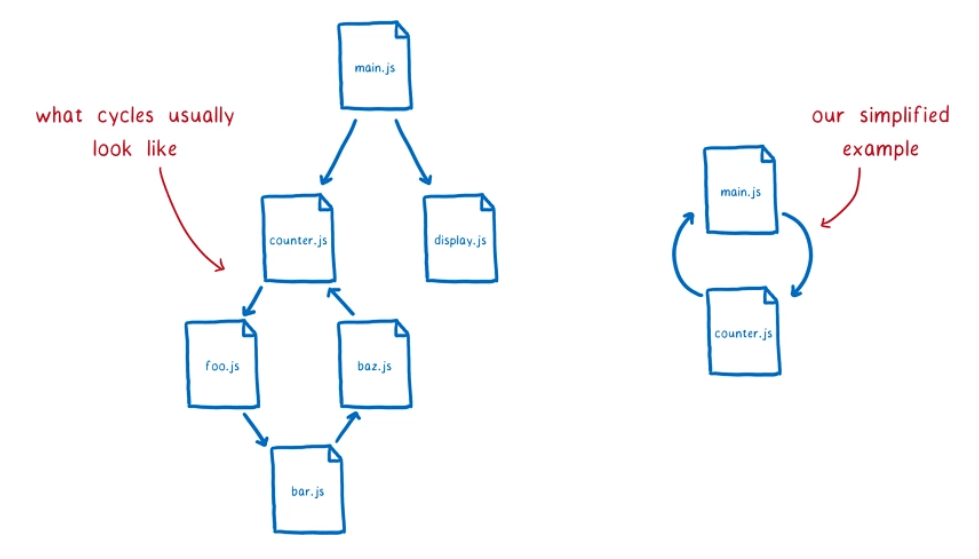
那我们之前谈到的循环依赖怎么处理呢?
在循环依赖关系中,您最终会在模块关系图中出现循环。你依赖我我依赖你,通常,这会变成很大的循环。
为了解释这个问题,我举个例子。
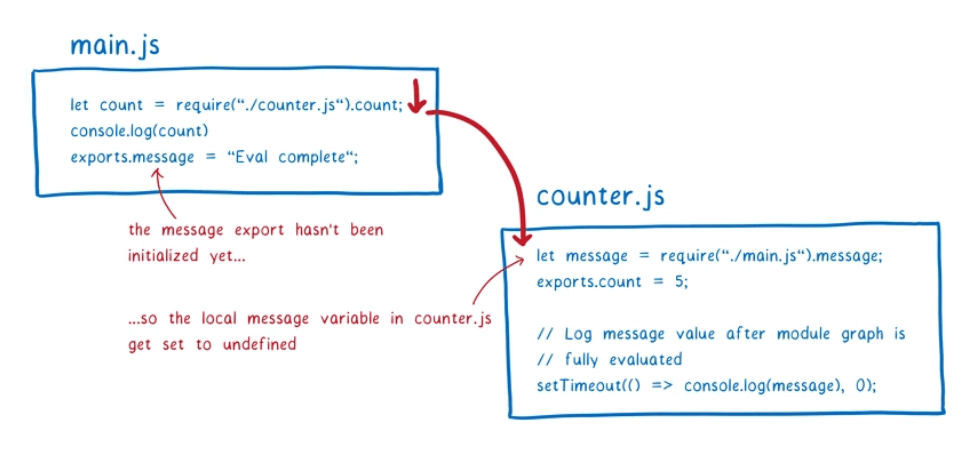
首先让我们看一下如果时CommonJS模块会时什么样的。首先,main模块将执行到require语句。然后它将去加载counter模块。
然后,counter模块将尝试从访问导出的对象message。但是由于尚未在main模块中执行,因此它将返回undefined。JS引擎将在内存中为局部变量分配空间,并将该值设置为undefined。

此时会一直运行持续到counter模块顶级代码的末尾。我们想看看是否最终将获得正确的message(在执行main.js之后),因此我们设置了超时时间。然后继续运行到main.js。
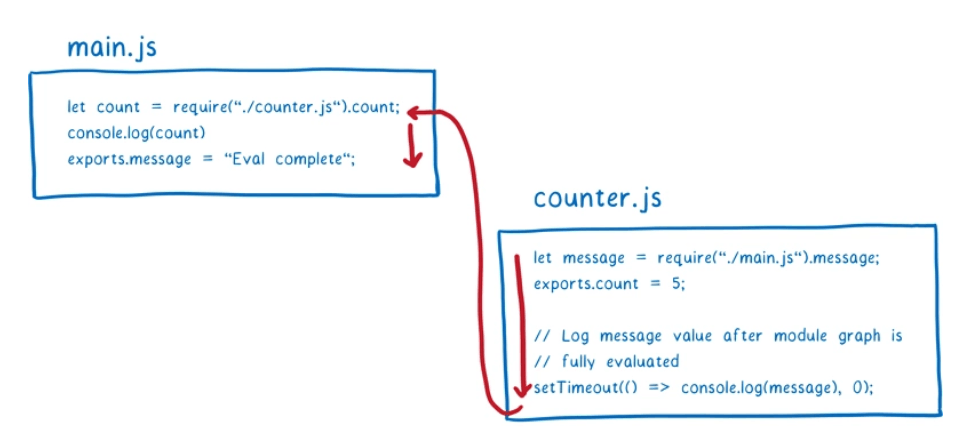
message变量将被初始化并添加到内存中。但是由于两者之间没有连接,因此message在counter模块中仍然是时undefined。
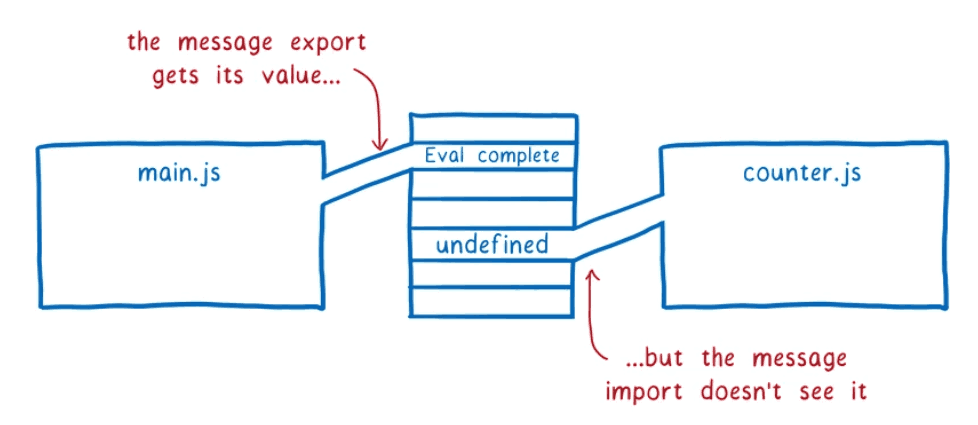
如果使用实时绑定处理导出,则counter模块最终将看到正确的值。到超时运行时,main.js的执行就已经完成并填充了值。
支持循环依赖是 ESM 设计之初就考虑到的一大因素。也正是这种分(三)阶段设计使其成为可能。