AI应用-知识库
背景
这篇文章拖了很久了。因为我之前带LMT团队,团队的主要工作内容就是处理客户现场问题,因为我要求过程留痕并且达到知识沉淀的效果,所以处理过程中产生了大量的文档,也就是很多经验都落到了文档上,比如linux系统(硬盘、系统版本、dns等)、docker、k8s、现场网络问题(防火墙、网闸等安全设备),也就是运维经常面临的问题,也有产品配置、bug等文档。
文档越来越多,但是却越来越难利用起来,我就想着把这些经验积累起来弄一个知识库,就像gpt一样,只要我输入有关问题他就能根据这些内容生成回答的内容,当然里面不仅仅是经验问答还需要有linux系统(硬盘、系统版本、dns等)、docker、k8s、现场网络问题(防火墙、网闸等安全设备)这些原始(原理)知识,还得有我们的产品知识。
这个知识库一是为了方便使用且能让我练手,二是当时公司推行创新活动,AI相关的案例也能为事业部加分。
开始
知识库的定位:小而美,因为是个人发起的前期申请到的服务器资源有限,而且功能非常单一明确,只需要满足知识库就行,不需要全能。
选型
通过一通查找对比,综合考虑,选择了Anything LLM或者Dify.AI+Ollama+Llama2小模型。
Anything LLM
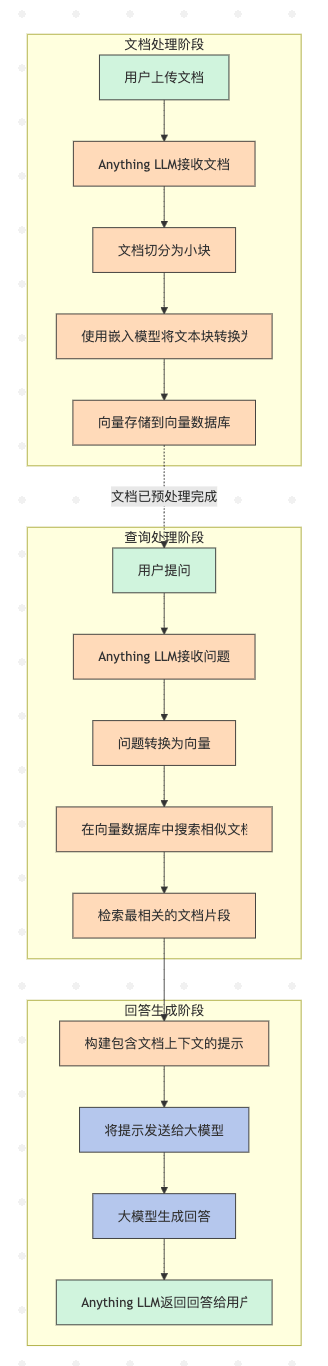
考虑的其中一点
是用Anything LLM这种开箱即用的还是用LangChain这种需要自己上手写代码的
Anything LLM和Dify.AI在其架构中广泛使用了LangChain组件,尤其是:
- 文档加载器(Document Loaders)
- 文本分割器(Text Splitters)
- 向量存储(Vector Stores)
- 检索器(Retrievers)
- 直接使用Anything LLM这种系统的好处
- 意味着即使不直接编写LangChain代码,您也在间接使用LangChain的强大功能。这有几个好处:
模块化设计 - 可以灵活替换组件(如切换向量数据库)
经过验证的架构 - 使用业界已验证的RAG实现方式
未来升级路径 - 如果您将来想更深入定制,可以直接使用LangChain API
- 意味着即使不直接编写LangChain代码,您也在间接使用LangChain的强大功能。这有几个好处:
- 坏处
- 没有深入的了解和实践经验
我当时其实想用LangChain的,环境都搭好了,但是因为没有系统的学习过,进度很慢,没法赶上评审节点,所以最终选择了使用Anything LLM这种简单的方式。
验证
Anything LLM+Ollama试了几种模型和Embedder,最终勉强得出一个组合Llama2:7B-chinese+bge-m3
还需要调整文档本身的内容,以及一些参数再多次尝试。
待续…
参考
https://docs.useanything.com/setup/llm-configuration/overview
https://github.com/Mintplex-Labs/anything-llm/blob/master/docker/HOW_TO_USE_DOCKER.md
https://adasci.org/anythingllm-for-local-execution-and-inferencing-of-llms-a-deep-dive/
https://itnext.io/deploy-flexible-and-custom-setups-with-anything-llm-on-kubernetes-a2b5687f2bcc
https://www.youtube.com/watch?v=4UFrVvy7VlA