遇见多表查询
背景
每个租户有自己的告警数据,少则几千多则几十万条数据,云平台提供了一个功能叫“全部告警跟踪”,该功能顾名思义,会展示所有租户的所有告警信息(刷新那一刻是实时的),还能支持过滤、搜索等操作,这功能据说上线没多久就有问题,比如点分页时不时会出现超时。但是因为这功能用的人非常少,且只有管理员才有权限,也就一直放着。
但是新版需求要求解决这个问题,因为现在是我维护这个功能,所以需要我先出个技术方案。
解法设计输出模板
解法设计的模板很多,但是我感觉稍微有点重,当前产品的节奏,没有那么多的时间和人力给我做那么详细的解法设计,所以简单梳理了一个简化版的解法设计,并与干系人达成了一致。
模板如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
1. 引言
- 背景说明
- 问题陈述(现状、目标)
- 关键术语
- 参考资料
2. 需求分析
- 核心诉求/期望交付的价值
- 非功要求
3. 约束条件
- 依赖项
- 假设项
4. 方案设计
- 可选方案对比(2-3个)
* 方案描述
* 优缺点分析
* 非功表现
- 推荐方案详细说明
* 架构设计
* 核心流程
* 关键设计点、算法伪代码(如果有必要)
5. 实施评估(因为团队自己做实施,所以加上这一章)
- 影响范围
- 实施成本
- 后续影响要分清楚解法设计和详细设计的核心区别:
- 解法设计:回答”用什么方案解决问题”
- 关注整体思路
- 多个方案对比选择
- 架构层面决策
- 详细设计:回答”如何具体实现这个方案”
- 已选定方案的具体技术实现细节
- 编码层面设计
- …
- 解法设计:回答”用什么方案解决问题”
开始
在这儿我就不原方不动的把整个解法贴出来了,只捡几个重点说。
需求分析
一定要记住,虽然咱们是干技术的,但是做解法的时候,一定先不要直接从技术的角度思考,先从业务的角度,还原业务场景,以及可能的演进需求,做到扩展性。
- 年少不懂事的时候,干过一段时间的产品助理,当时就学会做需求分析的几把斧:
tips:
- 搞清楚买单的人和使用的人谁?分别想解决什么问题,特别是买单的人容易被忽视。(使用方再满意,买单的人不满意也是白搭)
- 维护好与需求调研对象的关系(人情世故)
- 5W1H方法做需求分析和挖掘(找出底层需求,避免浮于表面文字)
- KANO方法对需求分级(找出痛点先解决,其它的都是锦上添花)
这儿的原始需求是管理员能对所有租户的告警跟踪查看,关注其下团队成员所负责的租户的处理情况,对工作进度有了解,同时可以随时查看核心客户的数据。
这样几句简单的话,应用5W1H+KANO拆解下:
5W1H分析:
WHO(谁)
- 主体:管理员
- 关注对象:团队成员、租户
WHAT(什么)
- 查看所有租户的告警跟踪情况
- 了解团队成员的工作进度
- 查看核心客户数据
WHEN(什么时候)
- 随时(需要实时或准实时的数据)
- 告警发生后的跟踪过程中
WHERE(在哪里)
- 系统内
WHY(为什么),更深入可以加入5Why方法,探寻源需求。
- 监督团队工作情况
- 及时了解核心客户状况
- 确保告警得到及时处理
HOW(怎么做)
- 提供告警跟踪查看、筛选功能
- 展示团队成员负责的租户处理进度
- 支持核心客户数据快速查看
KANO模型分析:
基本型需求(Must-be):
- 查看所有租户的告警记录
- 查看告警处理状态
期望型需求(Performance):
- 团队成员工作进度追踪
- 核心客户数据查看
兴奋型需求(Delighter):
- 数据分析和统计
这里能得到几个关键信息:
- 依然需要在活的实时的数据(需求已经明确)
- 需要搜索、分页、筛选(大数据量的场景)
- 后续很有可能需要统计数据(要考虑数据聚合)
- 非功
- 1000+租户,每个租户50w的告警,10s内刷出数据。
- 经费有限,且重新申请流程慢,额度小。
方案
- 方案1:ShardingSphere 自身实现。
广播表是ShardingSphere中的一个概念,指的是在所有分片中存在的表,每个分片都有完整的副本。当更新广播表时,所有分片都会同步更新。通常用于数据量不大且需要频繁关联查询的表,比如字典表。- 优点:简单,不用引入任何其他组件。
- 缺点:
- 数据量太大,无法在每个分片都复制全量数据。
- 方案2:ClickHouse(开源版)+Flink CDC
- 优点:
- CK在已在多个产品运用,学习成本较低。
- 可以支持复杂的查询、聚合需求。
- 适合离线分析。
- 单表查询性能极强。
- 缺点:
- 不支持事务。
- 集群部署成本高(官方没有提供Helm Chart。且ClickHouse集群扩展不方便,很多手动处理,不适合弹性扩展,集成k8s较难)。
- 删除/更新性能差,更适合批量追加。告警数据会经常变更,可能存在性能问题。
- 手动管理分片、分区、MergeTree等,维护成本较高。
- 优点:
- 方案3:Doris+Flink CDC
优点:
- 实时性高、支持高并发。
- 可以支持复杂的查询需求、聚合需求。
- 集群部署成本低(Doris,官方提供了Helm Chart,且适合弹性扩展,运维压力小)。
- 自动话程度高(分片、负载均衡、存储管理等)
- SQL友好
- 存算分离
缺点:
- 引入Doris新组件,可能会增加采购成本。
- 复杂的模糊搜索可能无法实现。
- 方案4:ES+Flink CDC
优点:
- 近实时,可能有秒级延迟。
- 可以支持复杂的查询需求(特别是全文检索)。
- 集群部署成本低(官方有Helm Chart和Operator,且适合弹性扩展,可无缝集成k8s,运维压力小)
缺点:
- 不支持事务
- 引入ES新组件,可能会增加较大采购成本(ES需要较多内存和SSD磁盘)。
- 很多时候需要手动处理,比如分片分步、设计索引、索引优化、GC 调优等,维护成本较高。
- 使用DSL,不是标准 SQL,学习成本较高。
推荐方案2
原因:
- 在活告警数据量可控,暂不考虑扩展。
- 系统已接入了CK,最低成本(学习、部署、购买)。
时序图
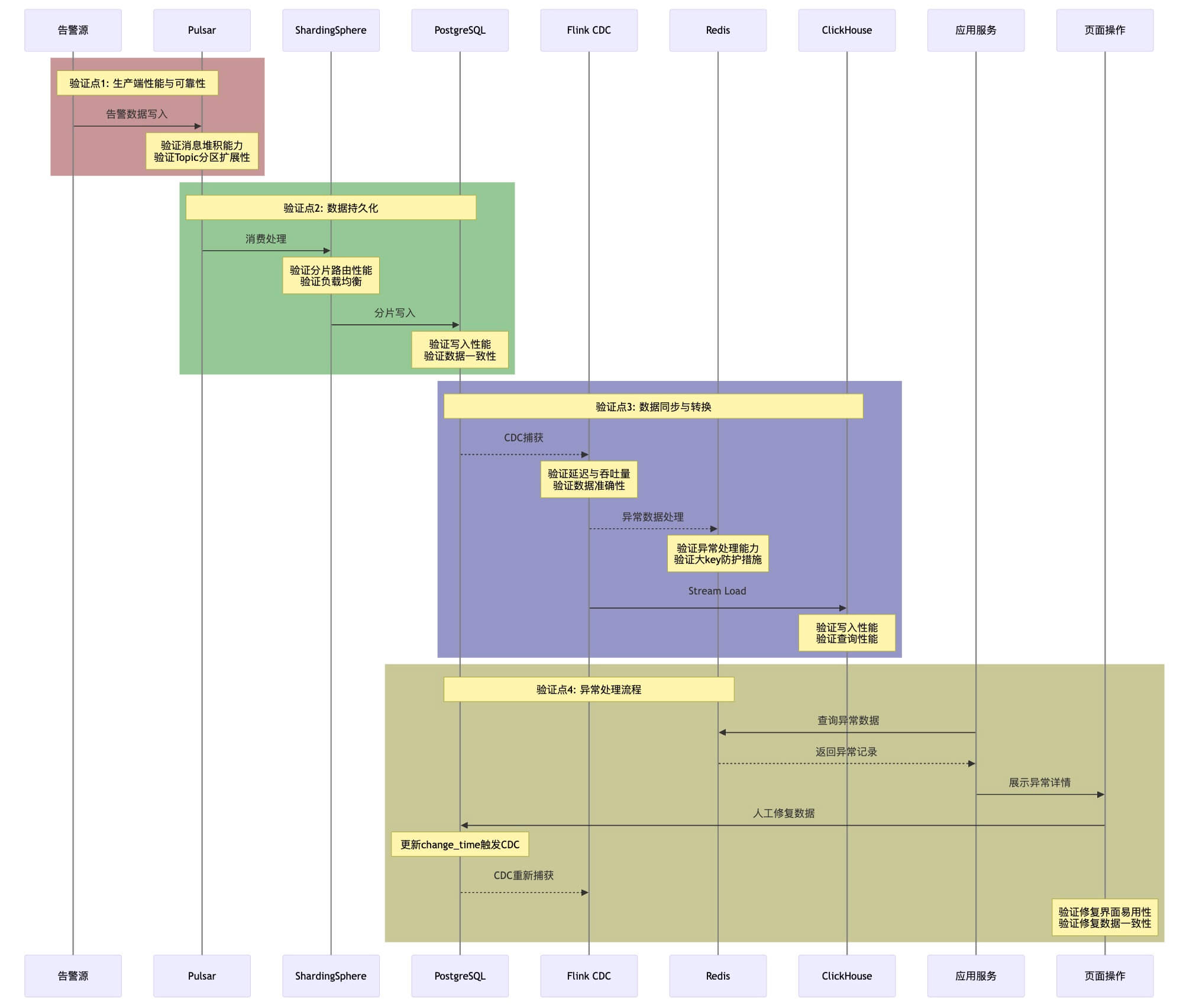
关键验证点
1、2验证点,由于前期已经做过验证,着重验证3、4就行,特别是更新和删除数据。
验证结果
按500个租户,每个租户5000在活告警,没问题,因为主要是验证可行性,没有那么严格的压测,图啥的当时就没留了。这块详设的时候会更具体严格一些。