0%
如何做职业规划
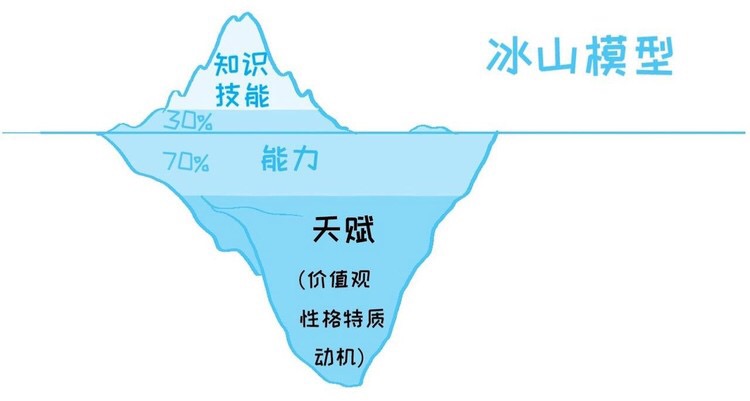
冰山模型
这玩意能比较通透的了解自己有几斤几两。
- 认知迷茫
- 危机感的缺失
- 物质需求基本满足,过于安逸
- 经验传承的断层
- 父辈那一代的经验和技能不能很好的借鉴
- 失败的自我认知教育
- 文化信仰的缺失
- 危机感的缺失
最终的表现就是,同样的起点,同样的终点,迷茫的人会走很多很多弯路。
如何做职业规划
找到人生目标
- 马斯洛需求理论
- 从欲望的角度
拆解人生目标
- 逻辑树
选择职业目标
- 工具
- 逻辑树,拆解自己的选择标准
- 决策矩阵
- 简化的矩阵,选择维度=2时
- 标准
- 感性因素(随心所欲)、理性因素(扬长避短、顺势而为)
- 工具
梳理职业路径
- 职业路径图,搞清楚所在职业整个的路径是什么。
- 对标管理,每个小目标都可以选择一个最佳实践
- 对标的目标的评估标准(CQ、RQ、IQ),找到自己与对标对象之间的差距,补足
制定发展计划
- 甘特图,小目标转化为计划
总结:工具包

延伸问题
- 如果第一步就卡住了怎么办
不着急,但是无论无何要把它搞出来。 - 为什么我的目标不够坚定
有红利期,就有人扑上去,那我扑不扑。
- 如果第一步就卡住了怎么办
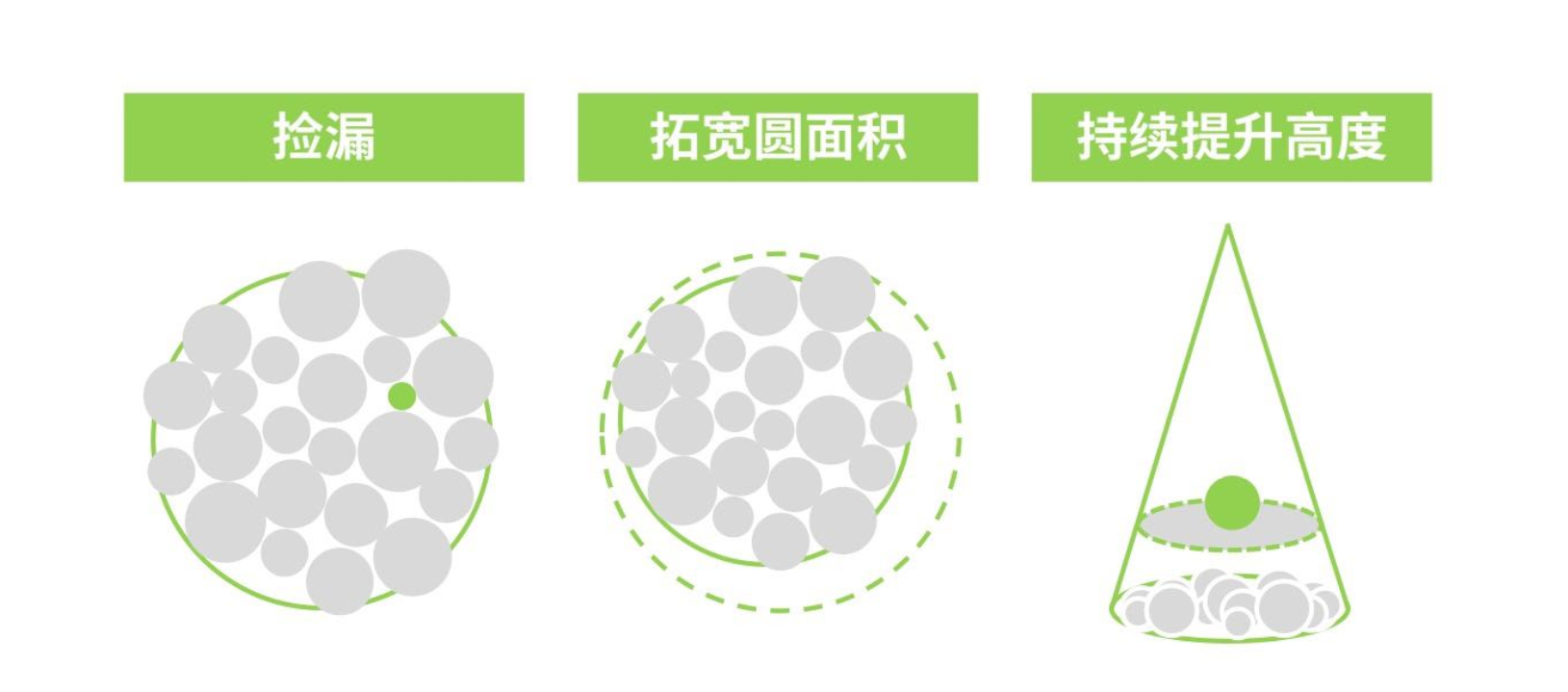
可能的解法
感谢:
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
根因分析
最近研发老大牵头组织了异常关于根因分析的讨论,目的在于让大家学会做根因分析,因为往往大家都是直接下结论(给答案),既容易发生矛盾也同时也没有解决根本问题。
现状
1.当有问题出现时,往往根据现象再加上以往的经验或者直接拍出一个结论,这种情况在短期内的效果是可以的,但是从长期来看会掩盖掉很多底层的问题。结果就是问题该出还出,不仅没有提升团队的效率反而降低了团队的效率。
2.当问题出现时就代表甩锅以及互怼的开始,没有经过根因分析,上来先下个结论,开始界定责任,然后开始扯皮。
根因分析
问题描述
(什么时间*-什么地点-什么产品-什么人物-发生什么故障现象-*造成什么影响)
示例
1 | 时间:2019-09-02 |
过程还原
直接叙述工作过程,有问题的环节或阶段,什么人,做了什么事,当时是怎么考虑的,在这个动作后结果是什么。
问题定位
描述最终定位到的直接原因是什么。举个例子,比如某段代码编写存在XXX错误
技术根因分析
引入环节:
- 产品设计是否有问题?
- 需求分析是否有问题?
- 设计环节是否有问题?
- 代码编写是否有问题?
- 其他
流出环节:
- 各评审环节是否有遗漏?
- 是否进行研发自测?
- 测试场景、测试用例是否覆盖全?
- 是否进行了系统测试?
- 其他?
确定关键根因是什么:
如果有多个根因在逻辑层次上相同,则取关键的原因,根因应该是具体的、客观的、在目前组织能力下可被改进的。
管理根因分析
- 流程/制度原因:
- 组织因素:
- 执行原因:
【帮助】流程/制度方面:考虑组织管理上是否有合适的流程、指导书、管理Checklist;
组织因素方面:考虑人员分配、个人技能、培训、组织环境等原因;
执行方面:考虑计划、监控、沟通方面的原因。
纠正、预防措施
| 根本原因 | 措施类型 | 措施内容 | 责任人 | 预定完成日期 |
|---|---|---|---|---|
| 技术根因: 例如,XX特性,在大规格、灵活配置等方面需求设计不充分 | 纠正措施 | 例如:对XX特性组织进行重新设计,刷新XX方案 | 2018/11/1 | |
| 预防措施 | 例如:更新××技术规范、工具、checklist等等 | |||
| 管理根因:组织管理、流程方面的原因,比如xx,没有按照流程,但是最终还是交付了。 | 纠正措施 | |||
| 预防措施 |
小结
上诉的内容,关键还是在于给一个框架,让问题发生人,根据框架的引导,能比较深刻的挖掘出问题的根因,按此框架填写后,往往会伴随着评审,最终判断分析的彻底性以及合理性。
当然这只是一种方式,一段时间实践下来,其实是有助于减少问题发生率以及增加个人问题的处理成本从而倒逼相关人员注意到质量的重要性。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
How To Master A Skill In A Short Period Of Time?
都怪我放荡不羁爱打野。
今天看了一个Dan lok的视频
https://www.youtube.com/watch?v=cC9DOCs4lo0&t=136s
Best way : Have a mentor
- it takes repetition
- learning and practice
transformation is doesn’t happen in islation
communicate with others
提高效率
最近个人成长KPI抓的严,为了能心安理得的继续IT事业,不管强迫自己多花时间在个人成长上。
刚好瞌睡遇到枕头,这两天经少数派,关注了B站的锦堂生活空间。
看到他的一个视频**”我保持高效率奋斗的5大因素”**,个人感觉是对我有用的。
一个远大的理想
- 理想要可衡量
- 要足够大
- 分段立目标,逐个完成
将所在领域内的偶像贴在工作墙上
- 时刻提醒自己,不放松。
绝对不要进入自己不感兴趣的领域
- 没有所谓的能力不足,只有你对这件事感不感兴趣
- 一定要确保你你再做着你自己喜欢的事情
学习新知识的时候,必须要不断的停下来思考
- 思考自己的缺点,怎么应用到我得生活和工作中。
- 费曼学习法,怎么让自己和别人明白,复杂的知识简单化
- 将简单化的知识点以口语化写进笔记本
准备一个笔记本记录激励你的话或者成功人士的小视频
在开始奋斗之前花几分钟时间看激励自己的东西,让自己亢奋起来

源引:
git实践
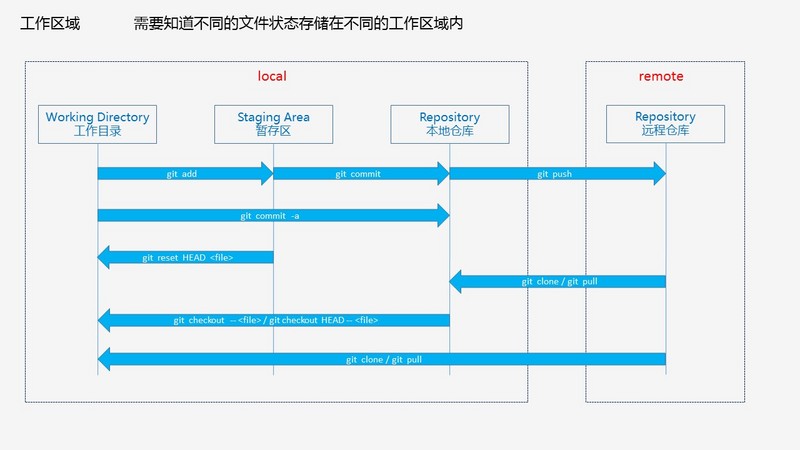
据说再2016年我就开始接触git,当时还用台式机、笔记本作为两个用户进行git的一些实践和原理的了解,但是正儿八经在项目中用git还是现在,经过一年多的实践呢,入了一些坑所以觉得是时候展现真正的技术了,简单积累一下我比较常用的。

** git提交规范 **
这块是很重要很重要的,在代码评审、问题追溯、代码回滚、代码培训等的时候都需要用到这个东西,但是团队内暂时还没有对此做硬性要求。不过我个人是一直比较注重提交的内容,因为以前吃过亏,没有友好的commit内容某些场景下很难定位。虽然我比较注重但是还是比较游击队的打法,最近看到了个东西叫commitizen,它可以配置一套标准的提交规范,所以准备用起来。
配置commitizen
https://juejin.im/post/5cbd1fdf5188250a546f565f
可借助工具使提交更加规范:安装cz-conventional-changelog,即使用第三方的提交模板,这儿表示用的AngularJS的提交模板
用husky配合git hooks 进行预检查
package.json
{
1 | "husky": { |
git 储藏
常用git stash命令:
(1)git stash save "save message" : 执行存储时,添加备注,方便查找,只有git stash 也要可以的,但查找时不方便识别。
(2)git stash list :查看stash了哪些存储
(3)git stash show :显示做了哪些改动,默认show第一个存储,如果要显示其他存贮,后面加stash@{$num},比如第二个 git stash show stash@{1}
(4)git stash show -p : 显示第一个存储的改动,如果想显示其他存存储,命令:git stash show stash@{$num} -p ,比如第二个:git stash show stash@{1} -p
(5)git stash apply :应用某个存储,但不会把存储从存储列表中删除,默认使用第一个存储,即stash@{0},如果要使用其他个,git stash apply stash@{$num} , 比如第二个:git stash apply stash@{1}
(6)git stash pop :命令恢复之前缓存的工作目录,将缓存堆栈中的对应stash删除,并将对应修改应用到当前的工作目录下,默认为第一个stash,即stash@{0},如果要应用并删除其他stash,命令:git stash pop stash@{$num} ,比如应用并删除第二个:git stash pop stash@{1}
(7)git stash drop stash@{$num} :丢弃stash@{$num}存储,从列表中删除这个存储
(8)git stash clear :删除所有缓存的stash
git 回滚
//回滚上一次提交
git reset HEAD~
// 修改最近一次提交的备注
git commit --amend
// 修改某一次提交的备注,最后的数字2指的是显示到倒数第几次
git rebase -i HEAD~2
git 合并
1 | //是将远程主机的最新内容拉到本地,用户在检查了以后决定是否合并到工作本机分支中 |
git 切换分支
//对于已经拉取到本地的分支之间的切换
git checkout 分支名
//对于还没有拉取到本地的分支
git checkout -b remote分支名 本地分支名
git 撤销merge
1 | //经常在切换分支时,一不小心就merge错了分支或者合并时遇到冲突想取消操作,这命令就好用了 |
git 撤销
1 | git reset --soft: 将分支回退到指定提交,工作区维持现状不变,暂存区会在现有基础上增加该commit之后的提交。 |
回退到某个版本并应用指定的几次提交
1 | 切换到目标分支上, 假如当前状态为新合并进了一条commit,只需执行 git reset --hard HEAD~1即可回退到合并前。 |
根据关键字搜索提交记录
1 | git log --all-match --grep=登录 |
吃力不讨好
话说2018.07.31的x安公司的谢XX和李XX,在摄像头下两人进行了比较随心所欲的肢体接触,网传是因为产品经理要求程序员实现APP主题根据手机壳变颜色的需求,程序员忍无可忍从而释放自我的过程。当然这是网传版本,据说完全不是那么回事。
但是为什么这个事件就那么红呢。我觉得有两方面的原因:
- 程序员一向是被整个社会调侃最多的职业之一(之一比较谦虚),热点够大。
- 网传的需求太他么奇葩,迎合了大多的吃瓜群众。
作为程序员其实我们为什么也觉得有趣,是因为产品和程序员多多少少都会有不对付(矛盾)的情况发生。这件事刚好映射了此情况。我个人觉得该矛盾的核心点还是在于同理心这一点上,双方好像都很难理解对方。其实主要就是很少站在对方的角度和位置上,客观的理解对象所说的事情。

讲的有点多了,为什么想说”吃力不讨好”,是因为本周周会复盘时,刚好遇到了一个同事出现了此情况,当事人肯定很难受也比较委屈,这位同事暂时起名小波,方便叙述。
当然这篇文章主要是站在技术人员的角度写的,其它职位的待我深入了解后再有资格叨叨。
为什么需要复盘一下呢,明面上的原因是小波任务delay了进而导致周目标delay了,在PO验收时结果有些不太理想。所以SM就拉着大家做了一下复盘,
流程是:
- 首先小波先说明一下整个delay的原因
- 分析根因
- 大家发表一下看法和建议
- 形成改进项或者规约之类的东西
- 团队是否认同
- 改进项的责任人进行跟进
大体的原因是在于,小波在研发时,鉴于程序员的伟大使命感,总想着抽象进而方便后人,但是在研发前期准备时不管是关键路径还是详设,都没能体现这块内容,关键是这块内容占用的时间还比较长,所以最终导致整个计划delay。这本身不是个问题,因为想法时好的,问题在于这是个”吃力不讨好”的事,因为这是过程产物,PO等人是看不到的,更大的问题是小波没有和任何人进行同步,一个人吭哧吭哧干了半天,那就大家都不知情,所以导致他很被动。
所以我给的建议是:
- 吃力不讨好的事一定得让干系人知道,好事不留名大多数情况下是扯淡的说法。
- 自己得有一定得心理准备或者做一定的心里建设,因为既然是吃力不讨好的事,那就不能指望所有人能念你的好。
当然最终团队形成了一些改进项
- 尽量提前在”关键路径“阶段列出所有研发内容,功能性的和非功能性的,使后面的工程计划能更加准确。
- 定义承载过程产物的文档格式以及标准,目的是为了体现研发过程。
- 周目标的check标准更加细化,能提升更早暴露风险的时间。
- 当在研发中遇到此类问题时,一定要马上同步到相关的人,评估计划方案之后再动手。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
编写可读代码的艺术
最近有个前辈大哥看我写的代码之后,温柔的推荐了我一本小书《编写可读性代码的艺术》
表明层次的改进
全局观注释
当某个类或者文件使用盖住是,比如是表示系统的入口点、数据如何在系统中流动等,具有全局意义的代码,写几句精心选择的话说明该代码的意义,不宜过大的篇幅。
总结性的注释
对函数做的事情进行总结,让读者在深入了解细节之前就能明白该函数的主旨。
写注释拆分成几件事:
- 不管你心里想什么,先把它写下来。
- 读一下注释,看看有没有什么地方可以改进的。
- 不断改进。
注释目的:
- 记录想法
- 为什么这样写(指导性)批注。
- 代码中的缺陷,使用像TODO或者XXX等这样的标记。
站在读者的立场上思考
- 预料哪些代码是读者会有疑问的,加上注释。
- 为普通读者意料之外的行为加上注释
- 用注释来总结代码块,使读者不至于迷失在细节中
怎样写出言简意赅的注释?
注释保持紧凑。不超过三行
避免使用不明确的代词,比如这、那。用有意义的名词代替,比如data、userList…
精确的描述函数的行为,比如“返回有效字符的个数”,哪些使有效字符哪些使无效字符?
某些涉及到比较复杂或者不太好用文字描述的函数,用输入输出的例子进行说明。比如“格式化字符串为下拉框格式”
Example: listToOptionTags([{id:1,name:'a'},...]) returns [{$$typeof: Symbol(react.element), type: ƒ Option(), key: "daa7f2d8-bfd9-11e9-8...},...]声明代码的意图,别描述字面上的意思。比如在一段for循环上写“遍历用户对象集合”,改成“以逗号分隔拼接所有用户的firstName属性”
具名函数参数,对难以理解的参数可以按照参数名对参数赋值,比如java中可以用嵌入注释的方式:
connect(10,false); 改成 connect(/*timeout_ms=*/30,/*use_encryption=*/false)
什么地方不需要注释?
- 能从代码本身中迅速地推断的事实。
- 用来说明烂代码(比如函数名取得不明所以…),这时考虑的应该是吧代码改好。
简化循环和逻辑
把控制流变得易读
条件判断,比较的左侧通常是经常变化的值,右侧通常为不变化的值,比如:
if(length>10)和if(10<=length),很明显前者更易读if/else的顺序,因为if/else的顺序可以自由变换,很多时候应该要考虑哪一种顺序更好,可以有以下准则:
- 通常情况下先处理正逻辑而不是负逻辑,比如if(haveUser)而不是if(!haveUser)
- 先处理简单的情况,这样的好处是可视范围内应该都能看到if/else
- 先处理有趣的或者更危险的情况,比如负逻辑 if not file…
所以有些规则是根据具体的情况而定的,需要我们自行判断该用哪一种形式,总之我们的目的是为了避免if/else顺序变得很别扭的情况。
三目运算符
该表达式的可读性是存在争议的,三目表达式是一行书写,当比较内容比较简单时,使用三目会让代码看上去很紧凑和易读,不过当比较的内容比较长或者比较复杂的时候,所有代码挤在一行,这样就变得冗长了。
关键思想:相较于追求最小化代码行数,一个更好的度量方法是最小化人们理解它的时间。所以可以遵循以下原则:默认情况下都用if/else,三目表达式只有在最简单的情况下使用。
用自然语言描述代码
用自然语言描述程序,然后用这个描述写出更自然的代码。
比较适用于稍微复杂一些的场景,通过这种方式,能根据描述用的词语和过程,进而拆分出一些子问题,从而简化代码,使代码看起来更自然。
本文引用的内容,如有侵权请联系我删除,给您带来的不便我很抱歉。
Personal Growth
来自Quora上的一个关于个人成长的问答,先摘录在这儿,成长计划可参考之。
Travel
Wake up early
Wake up and go to bed at the same time as much as possible
Get rid of toxic people
Focus on networking and building your network
Exercise daily, even if it is 5–10 minutes of intense exercise
Eat a high protein/high fat breakfast within 30 minutes of waking
Drink plenty of water throughout the day
Focus on the 80/20 rule
Focus on compounding activities. Like giving up alcohol or dramatically reducing it leads to more money and energy, which could result in more money if you reinvest the surplus. Same thing with negotiation and spending habits - Why the wealthy spend less on luxury: the 70/30 rule in finance
Read, read and read. Read about personal health, sales, management, marketing and personal finance - Best investment books for beginners
- 旅行
- 起得很早
- 尽可能多地醒来上床睡觉
- 摆脱有毒的人
- 专注于网络和建立网络
- 即使每天剧烈运动5-10分钟,也要每天运动
- 醒来30分钟内吃高蛋白/高脂早餐
- 全天多喝水
- 专注于80/20规则
- 专注于复合活动。 就像放弃酒精或大幅度减少酒精含量一样,它可以带来更多的金钱和精力,如果您将剩余资金再投资,可能会产生更多的钱。 具有谈判和消费习惯的东西-富人为何减少在奢侈品上的消费:70/30的金融规则
- 阅读,阅读和阅读。 了解有关个人健康,销售,管理,市场营销和个人理财的信息-适用于初学者的最佳投资书
代码写的好看一点
当自己都觉得代码看起来不爽,或者不好读懂时 ,这块代码一定写的有问题。
在《Clean Code》一书中Bob大叔认为在代码阅读过程中人们说脏话的频率是衡量代码质量的唯一标准。