📢 更新日志 :
2026-03-09 补充 HEARTBEAT.md 抢占主会话的排障记录,修正文中 Docker Compose 版本与记忆机制描述,新增“升级是否成功”的核验方法。
2026-03-06 新增 Step-3.5-Flash 接入与会话级 /model 切换说明,补充默认模型不切全局、只切当前会话的使用方式。
2026-03-03 新增”记录系统优化”章节,解决会话文件膨胀问题,添加自动归档和结构化存储方案。
AI提效
实战踩坑
写在前面 最近刷到不少 OpenClaw 的文章,演示零成本安装、智能体集群、国内部署经验。我手头正好有台配置不高的云服务器闲置着,决定动手搭建一个专属 AI 助手。
但这篇文章不是推广,是真实的部署踩坑记录 。整个过程历时数小时,遇到了 OOM 内存不足、配置验证失败、防火墙规则冲突等一系列问题,把完整的解决过程记录下来。
先说结论 :OpenClaw 确实能跑起来,但需要对 Docker、网络和 Linux 有一定了解,且内存配置要充足。
OpenClaw 是什么 OpenClaw 是一个开源的个人 AI 助手框架,核心价值在于:它不是只聊天的 AI,而是能动手干活的 AI 。
核心能力:
在 Telegram、Discord、Slack 等平台接收指令
操作文件系统、执行 Shell 命令、浏览网页
调用 API、读写数据库
跨会话持久化记忆
最重要的是——运行在自己的服务器上,数据完全掌控。
我的环境 搬瓦工买的一台机器,配置不高,平时捣鼓各种东西的。
配置项
实际环境
系统
Ubuntu 24.04.2 LTS
CPU
3 核
内存
2GB RAM
磁盘
39GB SSD
Docker
29.2.1
Docker Compose
v5.1.0
公网 IP
your-server-ip
⚠️ 重要提示 :2GB 内存对于源码构建来说不够,需要配置 Swap。
部署过程实录 第一步:安装 Docker Ubuntu 24.04 下安装 Docker 很顺利:
1 2 3 4 5 6 7 8 9 apt update && apt upgrade -y curl -fsSL https://get.docker.com | sh docker --version docker compose version
国内用户建议配置镜像加速,编辑 /etc/docker/daemon.json:
1 2 3 4 5 6 { "registry-mirrors" : [ "https://docker.1ms.run" , "https://dockerhub.icu" ] }
第二步:源码构建(第一个坑:OOM) 官方提供了 Docker 镜像,但我选择从源码构建以获得最新功能:
1 2 3 4 mkdir -p /opt/openclawcd /opt/openclawgit clone https://github.com/openclaw/openclaw.git cd openclaw
开始构建:
1 docker build -t openclaw:local -f Dockerfile .
🚨 第一个大坑:构建到 pnpm install 时容器被杀
查看日志发现是 OOM(内存不足) 。2GB RAM 在构建 Node.js 项目时不够用,pnpm install 直接占满内存导致进程被系统杀死。
解决方案:添加 Swap 空间
1 2 3 4 5 6 7 8 9 dd if =/dev/zero of=/swapfile bs=1G count=5chmod 600 /swapfilemkswap /swapfile swapon /swapfile free -h
添加 Swap 后重新构建,成功完成。
📷 安装过程 - 添加 Swap 解决 OOM :
第三步:配置 OpenClaw 创建 docker-compose.yml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 version: '3.8' services: openclaw-gateway: image: openclaw:local container_name: openclaw restart: unless-stopped environment: - HOME=/home/node - NODE_ENV=production volumes: - ./.openclaw:/home/node/.openclaw - ./.openclaw/workspace:/home/node/.openclaw/workspace ports: - "127.0.0.1:18789:18789" - "127.0.0.1:18790:18790" command: ["node" , "dist/index.js" , "gateway" , "--bind" , "lan" , "--port" , "18789" ]
🚨 第二个坑:配置验证极其严格
OpenClaw 对 openclaw.json 配置文件的校验非常严格,很多字段在官方文档中没有明确说明,但缺失会导致启动失败。
我遇到的错误:
1 2 3 ✖ Configuration validation failed: - gateway.mode is required - gateway.controlUi.allowedOrigins is required when using non-loopback bind
正确的最小配置 (openclaw.json):
1 2 3 4 5 6 7 8 9 10 11 12 { "gateway" : { "port" : 18789 , "mode" : "local" , "controlUi" : { "allowedOrigins" : [ "http://localhost:18789" , "http://127.0.0.1:18789" ] } , "auth" : { "token" : "your-secure-token-here" } } }
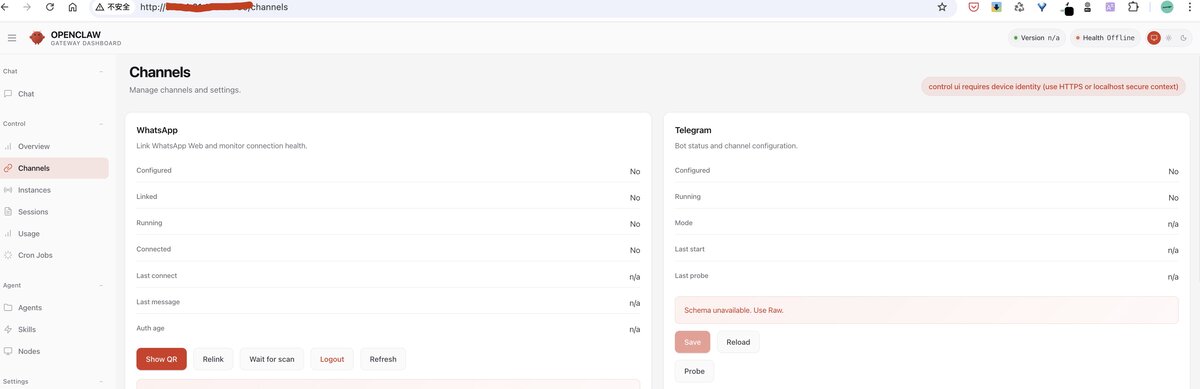
📷 OpenClaw Web UI 界面 :
关键注意点 :
gateway.mode 必须显式设置为 "local"gateway.controlUi.allowedOrigins 在使用非 localhost 绑定时是必需的gateway.bind 不能写在 JSON 中 (无效字段),必须通过 CLI 参数 --bind lan 设置
第四步:配置阿里云百炼模型 我选择使用阿里云百炼的 Coding Plan,配置 kimi-k2.5 作为主力模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 { "models" : { "mode" : "merge" , "providers" : { "bailian" : { "baseUrl" : "https://coding.dashscope.aliyuncs.com/v1" , "apiKey" : "YOUR_BAILIAN_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "kimi-k2.5" , "name" : "kimi-k2.5" , "input" : [ "text" , "image" ] , "contextWindow" : 262144 , "maxTokens" : 32768 } , { "id" : "qwen3.5-plus" , "name" : "qwen3.5-plus" , "input" : [ "text" , "image" ] , "contextWindow" : 1000000 , "maxTokens" : 65536 } ] } } } , "agents" : { "defaults" : { "model" : { "primary" : "bailian/kimi-k2.5" } } } }
第五步:配置 Telegram Bot 在 @BotFather 创建 Bot 并获取 Token。
🚨 第三个坑:配对码过期与 dmPolicy 冲突
1 2 3 4 5 6 7 8 9 { "channels" : { "telegram" : { "enabled" : true , "botToken" : "YOUR_BOT_TOKEN_HERE" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] } } }
初始配置时我加了 "dmPolicy": "open",结果与 allowFrom 白名单冲突,报错:
1 dmPolicy: open requires allowFrom: ["*"]
解决方案 :删除 dmPolicy 字段,直接使用 allowFrom 白名单。
启动服务:
1 2 docker compose up -d docker compose logs -f
看到日志显示 Telegram channel started 且没有错误,说明 Bot 已上线。
📷 Telegram Bot 配置成功 :
第六步:Google Workspace 集成(扩展能力) 这是 OpenClaw 真正强大的地方——通过 Google Workspace 集成,AI 可以帮你管理邮件、日历、文档。
OpenClaw 使用 gog skill 来访问 Google 服务(Gmail、Calendar、Drive、Docs、Sheets)。
6.1 创建 Google Cloud 项目
访问 Google Cloud Console
创建新项目(例如:openclaw-integration)
启用以下 API:
Gmail API
Google Calendar API
Google Drive API
Google Docs API
Google Sheets API
6.2 配置 OAuth 凭据
进入 APIs & Services > Credentials
点击 Create Credentials > OAuth client ID
选择 Desktop app 类型
记下 Client ID 和 Client Secret
6.3 配置 MCP 服务器 OpenClaw 通过 MCP (Model Context Protocol) 集成 Google Workspace。
在服务器上创建 MCP 配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mkdir -p /opt/openclaw/.openclaw/mcpcat > /opt/openclaw/.openclaw/mcp/google-workspace.json << 'EOF' { "mcpServers" : { "google-workspace" : { "command" : "npx" , "args" : ["-y" , "@gongchangio/mcp-google-workspace" ], "env" : { "GOOGLE_CLIENT_ID" : "your-client-id.apps.googleusercontent.com" , "GOOGLE_CLIENT_SECRET" : "your-client-secret" , "GOOGLE_REDIRECT_URI" : "http://localhost:18790/oauth2callback" } } } } EOF
6.4 重启 OpenClaw 并授权 1 2 3 4 5 cd /opt/openclawdocker compose restart docker compose logs -f | grep -i google
首次启动会显示 OAuth 授权链接,在浏览器中打开并授权后,会获得一个 code,将其填回即可。
6.5 实际使用场景 配置完成后,你可以通过 Telegram 让 AI 帮你:
管理邮件 :
“帮我查看今天的重要邮件,并回复需要处理的”
操作日历 :
“帮我查一下下周的会议安排,把周五下午的会议改到周四”
读写文档 :
“读取 Drive 里的 ‘项目计划.docx’,帮我总结要点并更新状态”
⚠️ 注意:Google OAuth 有权限范围限制
个人 Gmail 账户:直接可用
Google Workspace(企业账户):需要管理员授权
敏感范围(如删除邮件)需要额外验证
第七步:安全加固(重中之重) 🚨 第四个坑:Docker 绕过 INPUT 链的防火墙规则
我最初的防火墙配置:
1 2 iptables -I INPUT 1 -p tcp --dport 18789 -s 127.0.0.1 -j ACCEPT iptables -I INPUT 2 -p tcp --dport 18789 -j DROP
测试发现:公网仍然可以访问 Web UI!
原因 :Docker 在 DOCKER 链中插入了 ACCEPT 规则,且该链在 INPUT 链之前被处理。
正确的解决方案 :使用 DOCKER-USER 链
1 2 3 4 5 6 7 8 iptables -I DOCKER-USER 1 -p tcp -s 127.0.0.1 --dport 18789 -j ACCEPT iptables -I DOCKER-USER 2 -p tcp --dport 18789 -j DROP iptables -I DOCKER-USER 3 -p tcp -s 127.0.0.1 --dport 18790 -j ACCEPT iptables -I DOCKER-USER 4 -p tcp --dport 18790 -j DROP iptables-save > /root/iptables-rules.txt
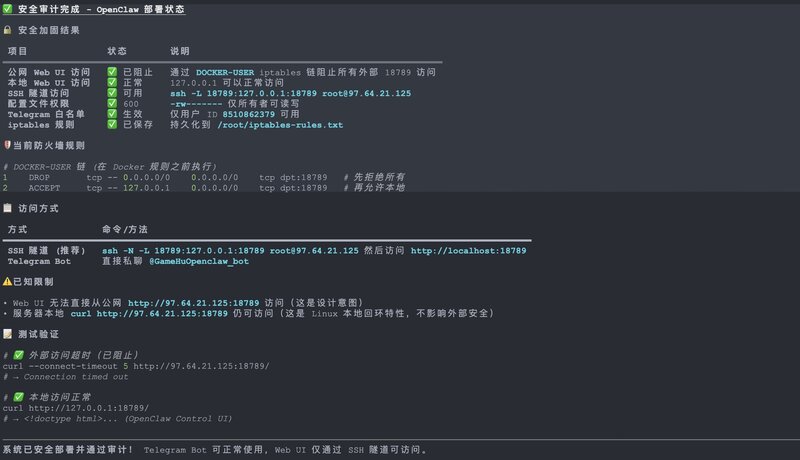
最终安全策略 :
项目
状态
配置文件权限
容器运行用户可读(避免 EACCES)
公网 Web UI
通过 DOCKER-USER 链完全阻止
本地 Web UI
127.0.0.1 可访问
Telegram 访问
仅白名单用户 ID 可用
外部访问方式
SSH 隧道
📷 最后安全检查 - 安全加固结果 :
SSH 隧道访问命令 :
1 2 ssh -N -L 18789:127.0.0.1:18789 root@your-server-ip
进阶玩法:持久记忆配置(第9步) OpenClaw 的持久记忆系统让它能跨会话记住你的偏好、项目信息和个人习惯。这是从”工具”升级为”助手”的关键。
记忆文件目录结构
路径
用途
文件类型
/home/node/.openclaw/memory/数据库存储(自动)
main.sqlite - 对话历史
/home/node/.openclaw/workspace/结构化记忆文件
MEMORY.md, USER.md
/home/node/.openclaw/workspace/memory/每日记忆归档
YYYY-MM-DD.md
核心记忆文件 1. USER.md - 用户档案 1 2 3 4 5 6 7 8 9 10 # USER.md - About Your Human - **Name:** Gamehu- **What to call them:** Gamehu- **Timezone:** Asia/Shanghai (UTC+8)## Context - **职业:** IT 行业,编程 + 团队管理- **需求:** 个人助手- **风格偏好:** 简单直接,不绕弯子
2. MEMORY.md - 长期记忆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # MEMORY.md - Long-term Memory ## Technical Stack - **Primary Languages:** Java, JavaScript, Python, Go- **Frameworks:** Spring Boot, React- **Cloud:** Alibaba Cloud, AWS### Preferences - **Code Style:** Clean, well-documented- **Learning Style:** Hands-on, project-based- **Dislikes:** Repetitive small talk### Current Projects - Building personal AI assistant- Managing development team
如何工作
自动记忆 :所有对话自动存入 SQLite,跨会话保持上下文结构化记忆 :AI 主动读取 MEMORY.md 了解你的背景和偏好持续更新 :OpenClaw 可以通过 heartbeat 或维护任务定期整理记忆,但主会话不建议配置成高频主动提醒模式
测试持久记忆 给 Bot 发送:
“记住我喜欢用 Go 语言写后端服务”
过一段时间再问:
“我之前告诉你我喜欢用什么语言?”
如果配置正确,Bot 应该能回答出 Go 。
进阶玩法:记录系统优化(第9.5步,新增) 在解决 compaction 卡死问题后,我意识到 OpenClaw 的会话记录管理还有很多优化空间。之前的经历是:会话文件在两天内膨胀到 1.4MB(603 条消息),导致系统卡死。为了防止类似问题再次发生,我设计并部署了一套结构化的记录管理系统 。
为什么需要记录系统优化
问题
优化前
优化后
会话文件膨胀
1.4MB(603条消息)
每日自动归档,单文件 < 100KB
数据管理
所有文件混在一起
结构化分类存储
查找历史
翻找 JSONL 文件
Markdown 摘要,一目了然
数据备份
手动复制
自动归档 + 一键导出
优化后的目录结构 我在 workspace 下创建了完整的分类存储结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 /root/.openclaw/workspace/ ├── memory/ # 记忆类数据 │ ├── daily/ # 每日摘要 (YYYY-MM-DD.md) │ ├── weekly/ # 每周汇总 │ └── archived/ # 长期归档 ├── records/ # 记录类数据 │ ├── conversations/ # 对话记录 (按月归档) │ │ └── 2026-03/ │ │ ├── 2026-03-03/ # 当日完整会话 │ │ └── 2026-03-03-sessions.tar.gz │ ├── tasks/ # 任务记录 │ │ ├── completed/ # 已完成任务 │ │ └── failed/ # 失败任务 │ ├── browser/ # 浏览器操作记录 │ │ ├── screenshots/ # 网页截图 │ │ └── page-dumps/ # 页面快照 │ └── files/ # 文件操作日志 ├── outputs/ # 输出类数据 │ ├── generated/ # AI 生成的文档 │ ├── exports/ # 导出文件 │ └── reports/ # 定时报告 └── logs/ # 日志类 ├── system/ # 系统日志 (archive-YYYY-MM-DD.log) ├── model/ # 模型调用记录 └── errors/ # 错误日志
自动归档脚本 创建 /root/.openclaw/workspace/archive-daily.sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #!/bin/bash WORKSPACE="/root/.openclaw/workspace" SESSIONS_DIR="/home/node/.openclaw/agents/main/sessions" DATE=$(date +"%Y-%m-%d" ) MONTH=$(date +"%Y-%m" ) mkdir -p "$WORKSPACE /records/conversations/$MONTH /$DATE " mkdir -p "$WORKSPACE /memory/daily" if [ -d "$SESSIONS_DIR " ]; then cp "$SESSIONS_DIR " /*.jsonl "$WORKSPACE /records/conversations/$MONTH /$DATE /" 2>/dev/null || true SESSION_COUNT=$(ls -1 "$SESSIONS_DIR " /*.jsonl 2>/dev/null | wc -l) SIZE=$(du -sb "$SESSIONS_DIR " 2>/dev/null | cut -f1) else SESSION_COUNT=0 SIZE=0 fi cat > "$WORKSPACE /memory/daily/${DATE} .md" << DAILYMD --- date: ${DATE} type: daily-summary sessions_count: ${SESSION_COUNT} sessions_size_kb: $((${SIZE} / 1024)) --- # 📅 ${DATE} 对话摘要 ## 📊 今日统计 - **日期**: ${DATE} - **星期**: $(date +%A) - **会话数**: ${SESSION_COUNT} - **数据大小**: $((${SIZE} / 1024)) KB ## 🏷️ 重要标签 - ## 💡 今日收获 - ## 📌 待办事项 - [ ] --- DAILYMD echo "[$(date) ] 归档完成: ${DATE} , ${SESSION_COUNT} 个会话" >> "$WORKSPACE /logs/system/archive-${DATE} .log"
赋予执行权限:
1 chmod +x /root/.openclaw/workspace/archive-daily.sh
配置定时任务 添加每天 23:00 自动执行归档:
1 2 3 4 5 (crontab -l 2>/dev/null | grep -v archive-daily; echo "0 23 * * * /root/.openclaw/workspace/archive-daily.sh >> /root/.openclaw/workspace/logs/system/cron.log 2>&1" ) | crontab - crontab -l
快捷命令配置 创建 /root/.openclaw/.aliases.sh,方便快速查看记录:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 alias oc-today='cat /root/.openclaw/workspace/memory/daily/$(date +%Y-%m-%d).md 2>/dev/null || echo "今日记录不存在"' alias oc-yesterday='cat /root/.openclaw/workspace/memory/daily/$(date -d yesterday +%Y-%m-%d 2>/dev/null || date -v-1d +%Y-%m-%d).md 2>/dev/null || echo "昨日记录不存在"' alias oc-archive='/root/.openclaw/workspace/archive-daily.sh' alias oc-stats='echo "=== OpenClaw 统计 ===" && echo "会话文件: $(ls -1 /home/node/.openclaw/agents/main/sessions/*.jsonl 2>/dev/null | wc -l)" && echo "每日摘要: $(ls -1 /root/.openclaw/workspace/memory/daily/*.md 2>/dev/null | wc -l)"' alias oc-size='du -sh /root/.openclaw/workspace/*/ 2>/dev/null | sort -h'
使用方法:
1 2 3 4 5 6 7 8 9 10 11 source /root/.openclaw/.aliases.shoc-today oc-archive oc-stats
Docker 容器内配置 为了让 OpenClaw Bot 也能执行归档,在 Docker 容器内创建归档脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 docker exec openclaw-openclaw-gateway-1 bash -c 'cat > /tmp/oc-archive.sh << "EOF" #!/bin/bash WORKSPACE="/home/node/.openclaw/workspace" SESSIONS="/home/node/.openclaw/agents/main/sessions" DATE=$(date +"%Y-%m-%d") MONTH=$(date +"%Y-%m") mkdir -p "$WORKSPACE/records/conversations/$MONTH/$DATE" COUNT=0 if [ -d "$SESSIONS" ]; then cp "$SESSIONS"/*.jsonl "$WORKSPACE/records/conversations/$MONTH/$DATE/" 2>/dev/null || true COUNT=$(ls -1 "$SESSIONS"/*.jsonl 2>/dev/null | wc -l) fi cat > "$WORKSPACE/memory/daily/$DATE.md" << DAILY --- date: $DATE type: daily-summary sessions_count: $COUNT --- # 📅 $DATE 对话摘要 ## 📊 统计 - 会话数: $COUNT ## 🏷️ 标签 - ## 💡 收获 - DAILY echo "✅ 归档完成: $DATE, $COUNT 个会话" EOF chmod +x /tmp/oc-archive.sh'
Telegram Bot 使用 配置完成后,你可以直接在 Telegram 中对 Bot 发送:
指令
功能
“归档今天的对话”
手动触发归档
“查看今天的记录”
显示今日摘要
“查看昨天的记录”
显示昨日摘要
“统计我的对话数量”
显示统计报告
每日摘要示例 生成的 Markdown 文件 (memory/daily/2026-03-03.md):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 --- date: 2026-03-03 type: daily-summary sessions_count: 5 sessions_ size_kb: 45 --- # 📅 2026-03-03 对话摘要 ## 📊 今日统计 - **日期** : 2026-03-03 - **星期** : Tuesday - **会话数** : 5 - **数据大小** : 45 KB ## 🏷️ 重要标签 - OpenClaw 配置 - 技能开发 ## 💡 今日收获 - 配置了自动归档系统 - 解决了会话文件膨胀问题 ## 📌 待办事项 - [ ] 测试归档功能 - [ ] 配置 Web 画廊
这种结构化的记录管理方式,让你可以:
快速回顾 - 每天打开 Markdown 文件即可看到当日概况防止膨胀 - 自动归档避免会话文件无限增长便于导出 - 重要记录可以轻松导出分享Telegram 管理 - 直接通过 Bot 指令管理记录
进阶玩法:自定义 Skill(第10步) OpenClaw 的 Skill 系统让你可以扩展 AI 的能力。我把自己的 Hexo 博客做成了 Skill,让 Bot 可以直接帮我创建博客文章。
我的 Hexo 博客 Skill 1. 创建脚本 在服务器上创建文章生成脚本 /opt/hexo-blog/create-post.sh:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #!/bin/bash BLOG_DIR="/opt/hexo-blog" POSTS_DIR="$BLOG_DIR /source/_posts" TITLE="${1:-新建文章} " CATEGORY="${2:-随笔} " TAGS="${3:-日常} " DATE=$(date +"%Y-%m-%d %H:%M:%S" ) FILENAME=$(echo "$TITLE " | sed 's/ /-/g' | tr '[:upper:]' '[:lower:]' )-$(date +"%Y%m%d" ).md mkdir -p "$POSTS_DIR " cat > "$POSTS_DIR /$FILENAME " << EOF --- title: $TITLE author: Gamehu date: $DATE tags: EOF IFS=',' read -ra TAG_ARRAY <<< "$TAGS " for tag in "${TAG_ARRAY[@]} " ; do echo " - $(echo $tag | xargs) " >> "$POSTS_DIR /$FILENAME " done cat >> "$POSTS_DIR /$FILENAME " << EOF categories: - $CATEGORY --- ## 写在前面 $TITLE <!-- more --> ## 正文 开始写作... --- EOF echo "✅ 文章创建成功: $POSTS_DIR /$FILENAME "
赋予执行权限:
1 chmod +x /opt/hexo-blog/create-post.sh
2. 创建 Skill 文件 OpenClaw 使用 SKILL.md 文件(不是 YAML),创建 ~/.openclaw/skills/hexo-blog/SKILL.md:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 --- name: hexo-blog description: Create and manage Hexo blog posts via shell script --- # Hexo Blog Skill Create new blog posts with proper front matter for Hexo. ## Usage Ask me to create a blog post: - "帮我创建一篇博客文章,标题是《XXX》,分类是技术,标签是 OpenClaw,AI"- "写一篇新文章,关于 Docker 使用心得"## Tools This skill uses the `shell` tool to execute `/opt/hexo-blog/create-post.sh` . ## Example ```bash /opt/hexo-blog/create-post.sh "文章标题" "分类" "标签1,标签2"
1 2 3 4 5 #### 3. 重启 OpenClaw 加载 Skill ```bash docker restart openclaw-openclaw-gateway-1
验证 Skill 是否加载:
3. 实际使用 在 @gamehu_kb_bot 里直接说:
“帮我创建一篇博客文章,标题是《OpenClaw 使用心得》,分类是工具,标签是 OpenClaw,AI”
Bot 会自动:
生成文件名 openclaw-shi-yong-xin-de-20260302.md
创建带完整 Front Matter 的 Markdown 文件
返回文件路径
Skill 核心概念
组件
作用
示例
Script 执行实际任务
Shell/Python 脚本
SKILL.md Skill 定义和说明
Markdown 文件(带 YAML frontmatter)
Directory Skill 存放位置
~/.openclaw/skills/<skill-name>/
更多 Skill 想法
Git Helper : 自动提交、查看状态、创建分支Docker Manager : 查看容器日志、重启服务File Organizer : 整理下载文件夹、重命名文件Daily Reporter : 生成每日工作总结
进阶玩法:浏览器控制(第12步) OpenClaw 内置了浏览器控制功能,让 AI 能够操作真实浏览器 执行网页任务,比如搜索信息、填写表单、抓取数据等。
🚨 坑位 14:Docker 镜像默认不包含浏览器
问题 Docker 部署后尝试使用浏览器功能时,报错:
1 2 [tools] browser failed: Error: No supported browser found (Chrome/Brave/Edge/Chromium on macOS, Linux, or Windows).
原因 默认的 Dockerfile 不会安装 Chromium/Playwright 浏览器,需要通过 --build-arg OPENCLAW_INSTALL_BROWSER=1 参数构建带浏览器的镜像。
解决方案:重新构建带浏览器的镜像 1. 停止当前服务 1 2 cd /opt/openclawdocker compose down
2. 构建带浏览器的新镜像 1 2 3 4 5 docker build -t openclaw:local-browser -f Dockerfile \ --build-arg OPENCLAW_INSTALL_BROWSER=1 \ --build-arg OPENCLAW_DOCKER_APT_PACKAGES="chromium xvfb" \ .
3. 修改环境变量使用新镜像 编辑 .env 文件:
1 2 3 4 5 OPENCLAW_IMAGE=openclaw:local OPENCLAW_IMAGE=openclaw:local-browser
4. 启动服务 5. 验证浏览器安装 1 2 3 4 5 6 7 8 docker exec openclaw-openclaw-gateway-1 \ ls -la /home/node/.cache/ms-playwright/
浏览器控制功能
功能
说明
网页浏览 访问指定 URL,获取页面内容
表单填写 自动填写并提交网页表单
信息搜索 在搜索引擎或电商网站搜索
数据抓取 提取网页中的结构化数据
截图保存 截取网页画面
使用示例 在 Telegram 中直接发送以下指令:
搜索信息 :
“打开浏览器,访问 GitHub,搜索 ‘openclaw’,告诉我前 3 个结果”
商品比价 :
“帮我在京东上搜索 ‘机械键盘’,找到评分最高的 3 个产品,记录价格”
数据抓取 :
“访问 https://news.ycombinator.com/,提取首页前 10 条新闻的标题和链接”
浏览器控制原理 1 用户指令 → OpenClaw Agent → 浏览器控制服务 → 无头 Chrome → 网页操作 → 结果返回
浏览器控制服务默认监听:http://127.0.0.1:18791/
注意事项
无头模式 :Docker 部署默认使用 headless 模式(无界面),适合服务器环境访问限制 :受限于服务器网络,无法访问需要登录的页面(除非提供 Cookie)执行时间 :复杂页面加载可能需要 10-30 秒安全提醒 :避免让 Bot 访问敏感网站或输入真实账号密码
实践任务 尝试让 Bot 完成以下任务:
✅ 信息收集:从某个网站抓取数据并整理
✅ 表单填写:自动填写一个在线表单
✅ 价格比较:在多个网站比较同一商品的价格
进阶玩法:多 Bot 配置(第11步) OpenClaw 支持配置多个 Telegram Bot ,每个 Bot 可以绑定不同的 Agent,实现分工协作。channels.telegram.accounts 还不够,想要真正隔离上下文,必须再加 agents.list + bindings。
我的多 Bot 架构
Bot
用户名
职责
对应 Agent
主助手
@GameHuOpenclaw_bot
通用对话、代码、写作
main
新闻助手
@gamehu_news_bot
科技新闻、每日简报
news
成长助手
@gamehu_growth_bot
学习计划、习惯追踪
growth
知识库助手
@gamehu_kb_bot
文档查询、笔记整理
kb
配置步骤 1. 在 @BotFather 创建多个 Bot 每个 Bot 都需要独立的 Token:
1 2 3 4 /main_bot - 主助手 /news_bot - 新闻助手 /growth_bot - 成长助手 /kb_bot - 知识库助手
2. 配置多账号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "channels" : { "telegram" : { "enabled" : true , "accounts" : { "main" : { "botToken" : "YOUR_MAIN_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] } , "news" : { "botToken" : "YOUR_NEWS_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] } , "growth" : { "botToken" : "YOUR_GROWTH_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] } , "kb" : { "botToken" : "YOUR_KB_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] } } } } }
3. 增加 Agent 路由绑定(关键) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "agents" : { "list" : [ { "id" : "main" , "default" : true , "workspace" : "/home/node/.openclaw/workspace" } , { "id" : "news" , "workspace" : "/home/node/.openclaw/workspace-news" } , { "id" : "growth" , "workspace" : "/home/node/.openclaw/workspace-growth" } , { "id" : "kb" , "workspace" : "/home/node/.openclaw/workspace-kb" } ] } , "bindings" : [ { "agentId" : "main" , "match" : { "channel" : "telegram" , "accountId" : "main" } } , { "agentId" : "news" , "match" : { "channel" : "telegram" , "accountId" : "news" } } , { "agentId" : "growth" , "match" : { "channel" : "telegram" , "accountId" : "growth" } } , { "agentId" : "kb" , "match" : { "channel" : "telegram" , "accountId" : "kb" } } ] }
⚠️ workspace 字段必须显式指定
这样每个 bot 会落到不同 agent,会话文件分目录保存,记忆文件也完全隔离。
4. 为每个 Agent 创建独立 Workspace 每个 agent 对应一个独立目录,在服务器上创建:
1 2 3 mkdir -p /root/.openclaw/workspace-newsmkdir -p /root/.openclaw/workspace-growthmkdir -p /root/.openclaw/workspace-kb
每个目录下的结构:
1 2 3 4 5 6 workspace-news/ ├── SOUL.md ├── MEMORY.md ├── USER.md ├── AGENTS.md └── memory/
每个 AGENT.md 定义该 Bot 的专业领域和行为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # News Agent ## Role 你是一个科技新闻助手,专注于提供最新、最有价值的科技资讯。 ## Capabilities - 追踪科技行业动态- 总结技术文章要点- 提供每日新闻简报## Style - 简洁明了,重点突出- 提供信息来源链接- 主动推送重要消息
4. 重启服务 查看日志确认所有 Bot 启动:
1 2 3 4 [telegram] [main] starting provider (@GameHuOpenclaw_bot) [telegram] [news] starting provider (@gamehu_news_bot) [telegram] [growth] starting provider (@gamehu_growth_bot) [telegram] [kb] starting provider (@gamehu_kb_bot)
实际使用效果
上下文隔离 :在 @gamehu_growth_bot 聊学习计划,切到 @gamehu_news_bot 问新闻,再回到 growth Bot,它还记得刚才的学习话题专业化分工 :每个 Bot 专注于自己的领域,回复质量更高并行对话 :可以同时和多个 Bot 对话,互不干扰
⚠️ 注意事项
多账号配置时,不要 在顶层设置 botToken,全部放在 accounts 下
每个 accountId(如 main、news、growth、kb)必须是唯一的
账号名不要用 default,会和系统默认账号冲突
进阶玩法:定时任务推送到指定 Bot(第11.5步) 配置好多 Bot 之后,你可能会发现一个问题:OpenClaw 里设置的定时任务(cron job),推送结果全都跑到了 main bot,而不是对应的 bot 。
🚨 坑位 17:定时任务 delivery 缺少 accountId
问题现象 在 OpenClaw Web UI 里配了新闻推送任务,时间一到,消息却出现在了 @GameHuOpenclaw_bot(main bot),而不是 @gamehu_news_bot。
根本原因 OpenClaw 的定时任务存储在 ~/.openclaw/cron/jobs.json,每个任务的 delivery 字段控制推送目标。如果只写了 to(用户 ID),没有写 accountId,OpenClaw 不知道用哪个 bot 账户推送,默认走 main。
另外,to 只负责“推给谁”(用户 / 群 / 频道),accountId 负责“用哪个 bot 发”。这两个字段职责不同,缺一不可。
有问题的配置:
1 2 3 4 5 "delivery" : { "mode" : "announce" , "channel" : "telegram" , "to" : "YOUR_USER_ID" }
解决方案 在每个 job 的 delivery 中加上 accountId,同时在 job 顶层加上 agentId。建议把执行超时提到 120 秒(字段 timeoutSeconds):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "id" : "xxx" , "agentId" : "news" , "name" : "每日新闻推送" , "timeoutSeconds" : 120 , "payload" : { "kind" : "agentTurn" , "message" : "执行新闻脚本并发送结果给用户" } , "delivery" : { "mode" : "announce" , "channel" : "telegram" , "accountId" : "news" , "to" : "YOUR_USER_ID" } }
推送目标的两种正确姿势 方案 A(推荐):同一个用户,按不同 Bot 身份推送 这种方式最适合你当前“4 个 Bot 各司其职”的场景。to 全部写你的用户 ID,accountId 分别写 main/news/growth/kb,消息会显示来自对应 bot。
1 2 3 4 5 6 7 8 9 10 { "agentId" : "news" , "timeoutSeconds" : 120 , "delivery" : { "mode" : "announce" , "channel" : "telegram" , "accountId" : "news" , "to" : "YOUR_USER_ID" } }
方案 B:推送到群 / 频道 / 话题 如果要发到频道,不要填 bot 用户名(如 @gamehu_news_bot),而是填频道 chat id(通常是 -100...)。并确保对应 bot 已加入目标群/频道且有发言权限。
1 2 3 4 5 6 7 8 9 10 { "agentId" : "news" , "timeoutSeconds" : 120 , "delivery" : { "mode" : "announce" , "channel" : "telegram" , "accountId" : "news" , "to" : "-1001234567890" } }
各任务对应关系
任务
agentId
accountId
推送到
每日新闻推送
news
news
@gamehu_news_bot
每日成长提醒
growth
growth
@gamehu_growth_bot
每周知识库总结
kb
kb
@gamehu_kb_bot
其他通用任务
main
main
@GameHuOpenclaw_bot
修改完 jobs.json 后重启服务即可生效:
1 cd /opt/openclaw && docker compose restart
进阶玩法:接入 Step-3.5-Flash,并支持会话级切换(第11.6步) 最近我把底层模型又补了一档:Step-3.5-Flash。但这里有个非常容易搞混的点,我一开始也踩了坑:
🚨 坑位 18:想要“随时切模型”,不等于要改全局默认模型
如果你直接把 agents.defaults.model.primary 全局切到 Step,看起来省事,实际上会把别的会话、别的 Bot,甚至定时任务一起带偏。
全局默认模型继续保持不变 ,我这里还是 bailian/kimi-k2.5把 step/step-3.5-flash 注册成一个可选 provider
需要的时候,直接在 当前 Telegram 会话 里发送 /model ... 切换
Step provider 配置示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 { "models" : { "mode" : "merge" , "providers" : { "bailian" : { "baseUrl" : "https://coding.dashscope.aliyuncs.com/v1" , "apiKey" : "YOUR_BAILIAN_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "kimi-k2.5" , "name" : "kimi-k2.5" , "contextWindow" : 256000 , "maxTokens" : 8192 } ] } , "kimi" : { "baseUrl" : "https://api.moonshot.cn/v1" , "apiKey" : "YOUR_KIMI_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "moonshot-v1-128k" , "name" : "moonshot-v1-128k" , "contextWindow" : 131072 , "maxTokens" : 8192 } ] } , "step" : { "baseUrl" : "https://api.stepfun.com/v1" , "apiKey" : "YOUR_STEP_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "step-3.5-flash" , "name" : "Step 3.5 Flash" , "contextWindow" : 256000 , "maxTokens" : 8192 } ] } } } , "agents" : { "defaults" : { "model" : { "primary" : "bailian/kimi-k2.5" } , "contextTokens" : 131072 } } }
为什么我把 contextTokens 调到 131072 这不是说 kimi-k2.5 或 step-3.5-flash 只能吃 128k,而是为了兼容我现在保留的第三档模型 moonshot-v1-128k。
如果你想做到:
默认走百炼
需要时切 Step
偶尔还能切回 Moonshot 做速度/成本对比
那最稳的双档/三档基线,就是把 contextTokens 先压在 131072 。这样:
bailian <-> step 切换时,几乎不会因为窗口变化引发额外压缩切到 moonshot-v1-128k 时,也不会立刻超限
当前会话切换命令 直接在 Telegram 里发:
1 2 3 4 5 6 /models /models step /model status /model step /model bailian/kimi-k2.5 /model kimi/moonshot-v1-128k
这里要强调 3 个边界:
只影响当前会话 不会清空 SOUL.md / MEMORY.md / USER.md / AGENTS.md 不会影响 cron 定时任务
也就是说,这种切换本质上是“会话级模型覆盖”,不是“全局改配置”。
切模型会不会丢上下文 长期记忆不会丢,工作区画像也不会丢。真正会受影响的是短期上下文压缩 :
从 bailian/kimi-k2.5 切到 step/step-3.5-flash,因为两边都是大窗口,风险很低
从 bailian 或 step 切到 moonshot-v1-128k,因为窗口更小,下一轮可能触发更激进的 compaction
所以我现在的原则很简单:
平时默认:bailian/kimi-k2.5
需要测试 Step:/model step
需要切回稳定默认:/model bailian/kimi-k2.5
需要做小窗口对比:/model kimi/moonshot-v1-128k
⚠️ 如果你想支持“切换模型 step”这种中文自然语言,而不是 /model step,那是另外一层 parser 改造,不是 OpenClaw 开箱即用能力。
完整配置文件参考 openclaw.json (多 Bot 生产版本,已脱敏,包含 compaction 修复):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 { "gateway" : { "port" : 18789 , "mode" : "local" , "controlUi" : { "allowedOrigins" : [ "http://localhost:18789" , "http://127.0.0.1:18789" ] } , "auth" : { "token" : "your-secure-token-here" } } , "models" : { "mode" : "merge" , "providers" : { "bailian" : { "baseUrl" : "https://coding.dashscope.aliyuncs.com/v1" , "apiKey" : "YOUR_BAILIAN_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "kimi-k2.5" , "name" : "kimi-k2.5" , "reasoning" : false , "input" : [ "text" , "image" ] , "cost" : { "input" : 0 , "output" : 0 , "cacheRead" : 0 , "cacheWrite" : 0 } , "contextWindow" : 256000 , "maxTokens" : 8192 } ] } , "kimi" : { "baseUrl" : "https://api.moonshot.cn/v1" , "apiKey" : "YOUR_KIMI_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "moonshot-v1-128k" , "name" : "moonshot-v1-128k" , "reasoning" : false , "input" : [ "text" , "image" ] , "cost" : { "input" : 0 , "output" : 0 , "cacheRead" : 0 , "cacheWrite" : 0 } , "contextWindow" : 131072 , "maxTokens" : 8192 } ] } , "step" : { "baseUrl" : "https://api.stepfun.com/v1" , "apiKey" : "YOUR_STEP_API_KEY" , "api" : "openai-completions" , "models" : [ { "id" : "step-3.5-flash" , "name" : "Step 3.5 Flash" , "reasoning" : false , "input" : [ "text" , "image" ] , "cost" : { "input" : 0 , "output" : 0 , "cacheRead" : 0 , "cacheWrite" : 0 } , "contextWindow" : 256000 , "maxTokens" : 8192 } ] } } } , "agents" : { "defaults" : { "model" : { "primary" : "bailian/kimi-k2.5" } , "contextTokens" : 131072 , "compaction" : { "mode" : "safeguard" , "reserveTokensFloor" : 24000 , "identifierPolicy" : "strict" , "memoryFlush" : { "enabled" : true , "softThresholdTokens" : 6000 } } } , "list" : [ { "id" : "main" , "default" : true } , { "id" : "news" } , { "id" : "growth" } , { "id" : "kb" } ] } , "bindings" : [ { "agentId" : "main" , "match" : { "channel" : "telegram" , "accountId" : "main" } } , { "agentId" : "news" , "match" : { "channel" : "telegram" , "accountId" : "news" } } , { "agentId" : "growth" , "match" : { "channel" : "telegram" , "accountId" : "growth" } } , { "agentId" : "kb" , "match" : { "channel" : "telegram" , "accountId" : "kb" } } ] , "session" : { "scope" : "per-sender" , "reset" : { "mode" : "idle" , "idleMinutes" : 30 } , "maintenance" : { "mode" : "enforce" , "pruneAfter" : "7d" , "maxEntries" : 120 } } , "channels" : { "telegram" : { "enabled" : true , "dmPolicy" : "pairing" , "groupPolicy" : "allowlist" , "historyLimit" : 30 , "accounts" : { "main" : { "botToken" : "YOUR_MAIN_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] , "dmPolicy" : "pairing" , "groupPolicy" : "allowlist" , "streaming" : "off" } , "news" : { "botToken" : "YOUR_NEWS_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] , "dmPolicy" : "pairing" , "groupPolicy" : "allowlist" , "streaming" : "off" } , "growth" : { "botToken" : "YOUR_GROWTH_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] , "dmPolicy" : "pairing" , "groupPolicy" : "allowlist" , "streaming" : "off" } , "kb" : { "botToken" : "YOUR_KB_BOT_TOKEN" , "allowFrom" : [ "YOUR_TELEGRAM_USER_ID" ] , "dmPolicy" : "pairing" , "groupPolicy" : "allowlist" , "streaming" : "off" } } } } }
⚠️ 关键提示 :
如果你保留多档模型可切换,contextTokens 不要盲目拉满;我现在用 131072 作为三档模型共存时的安全基线。
浏览器功能 :默认镜像不包含 Chromium,需要使用 --build-arg OPENCLAW_INSTALL_BROWSER=1 构建 openclaw:local-browser 镜像多 Bot 场景必须配置 bindings,否则 direct chat 默认会落到主会话桶,容易串上下文。
如果你临时切到 moonshot-v1-128k,继续保持 contextTokens <= 131072,避免再次出现 compaction 超限。
单 Bot 简化版(含 compaction 修复):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 { "gateway" : { "port" : 18789 , "mode" : "local" , "controlUi" : { "allowedOrigins" : [ "http://localhost:18789" , "http://127.0.0.1:18789" ] } , "auth" : { "token" : "your-secure-token" } } , "models" : { "providers" : { "bailian" : { "baseUrl" : "https://coding.dashscope.aliyuncs.com/v1" , "apiKey" : "YOUR_API_KEY" , "models" : [ { "id" : "kimi-k2.5" , "contextWindow" : 256000 , "maxTokens" : 8192 } ] } } } , "agents" : { "defaults" : { "model" : { "primary" : "bailian/kimi-k2.5" } , "contextTokens" : 131072 , "compaction" : { "mode" : "safeguard" , "reserveTokensFloor" : 24000 } } } , "session" : { "reset" : { "mode" : "idle" , "idleMinutes" : 30 } , "maintenance" : { "mode" : "enforce" , "pruneAfter" : "7d" , "maxEntries" : 120 } } , "channels" : { "telegram" : { "enabled" : true , "historyLimit" : 30 , "botToken" : "YOUR_BOT_TOKEN" , "allowFrom" : [ "YOUR_USER_ID" ] } } }
踩坑总结
坑位
问题
解决方案
1
构建时 OOM
添加 5GB Swap 空间
2
gateway.mode 缺失必须显式设置 "mode": "local"
3
controlUi.allowedOrigins 缺失非 localhost 绑定时必须配置
4
gateway.bind 配置无效必须使用 CLI 参数 --bind lan
5
Telegram 配对失败
删除 dmPolicy,使用 allowFrom 白名单
6
防火墙不生效
使用 DOCKER-USER 链而非 INPUT 链
7
Google OAuth 授权失败
确保 Redirect URI 与配置完全一致
8
MCP 服务器无法启动
检查 npx 是否可用,网络是否通畅
9
多 Bot 配置时 default 账号冲突
避免使用 default 作为 accountId,改用 main、news 等
10
多 Bot 顶层 botToken 被覆盖
使用 accounts 时,顶层不要设置 botToken
11
Skill 脚本权限不足
确保脚本有执行权限 chmod +x script.sh
12
Skill 中文字符处理
使用 `echo
13
Compaction 卡死导致无响应
配置合理 contextTokens + 设置 historyLimit + 启用 session.maintenance
14
Docker 镜像无浏览器
使用 --build-arg OPENCLAW_INSTALL_BROWSER=1 重新构建镜像
15
镜像体积过大 (5.7GB)
使用多阶段构建 + node:22-bookworm-slim 基础镜像
16
会话记录膨胀失控
部署结构化记录系统 + 每日自动归档 + 分类存储
17
定时任务推送全到 main bot
jobs.json 每个 job 加 agentId + delivery.accountId
18
想切 Step 却误改全局默认模型
保持默认模型不动,使用 /model ... 做会话级切换
19
HEARTBEAT.md 抢占 main 主会话保留 heartbeat,但改成低风险静默版;主动提醒交给 cron 或其他 bot
镜像优化指南(第15坑) 问题:镜像体积过大 OpenClaw 默认构建的镜像体积巨大:
openclaw:local: 4.4GB openclaw:local-browser: 5.7GB
在 2GB 内存的服务器上,光是镜像就占满了磁盘。
原因分析
问题
说明
占用
单阶段构建 构建依赖和生产代码混在一起
~1GB
未清理 devDependencies 开发依赖未删除
~500MB
bookworm 基础镜像 完整 Debian 系统
~1GB
Chromium + Playwright 浏览器全套
~1.7GB
解决方案:多阶段构建 创建 Dockerfile.optimized:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 FROM node:22 -bookworm AS builderWORKDIR /app RUN corepack enable COPY package.json pnpm-lock.yaml ./ RUN pnpm install --frozen-lockfile COPY . . RUN pnpm build && pnpm ui:build RUN pnpm prune --prod FROM node:22 -bookworm-slim AS productionRUN apt-get update && apt-get install -y --no-install-recommends \ ca-certificates curl git \ && rm -rf /var/lib/apt/lists/* WORKDIR /app COPY --from=builder /app/dist ./dist COPY --from=builder /app/node_modules ./node_modules COPY --from=builder /app/package.json ./ COPY --from=builder /app/openclaw.mjs ./ RUN groupadd -r nodeuser && useradd -r -g nodeuser nodeuser RUN chown -R nodeuser:nodeuser /app USER nodeuserENV NODE_ENV=productionEXPOSE 18789 18790 CMD ["node" , "openclaw.mjs" , "gateway" , "--allow-unconfigured" ]
构建优化版镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cd /opt/openclawdocker build \ --target production \ -t openclaw:slim \ -f Dockerfile.optimized \ . docker build \ --target browser \ -t openclaw:slim-browser \ -f Dockerfile.optimized \ .
优化效果对比
镜像
原体积
优化后
节省
openclaw:local4.4GB
openclaw:slim 2.5GB 43% ↓
openclaw:local-browser5.7GB
openclaw:slim-browser 3.5GB 39% ↓
使用优化版镜像 修改 .env 文件:
1 2 3 4 5 OPENCLAW_IMAGE=openclaw:slim
然后重启服务:
进一步优化建议
使用 Alpine 基础镜像 (极致精简)
启用 Docker 镜像压缩
1 docker build --compress ...
定期清理无用镜像
重大坑位详解:Compaction 卡死问题(第13坑) 部署运行几天后,我遇到了一个极其隐蔽但致命 的问题:Telegram Bot 突然不响应了,或者响应需要等 5 分钟以上。
现象
发送消息后 Bot 无响应
日志卡在 embedded run compaction start 不动
服务重启后短暂正常,很快又卡死
根因分析 深度诊断后发现了两个根本原因 :
根因 1:contextTokens 不匹配 OpenClaw 默认上下文预算与实际模型窗口不一致时,会导致系统误判可用空间,compaction 后仍然超限(日志显示使用了 145.7%)。
所以一定要注意不同的模型一定要修改响应的配置。
根因 2:无 historyLimit 限制 所有历史消息(603 条)全部进入上下文,而不是只取最近的几十条。两天内会话文件膨胀到 1.4MB,每次 compaction 都要扫描全部历史。
触发因素:输出被频繁截断 maxTokens 配得过小会让长任务反复截断并补发,间接加速会话膨胀。它不是唯一根因,但会放大卡顿问题。
解决方案 需要添加三组关键配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 { "agents" : { "defaults" : { "contextTokens" : 131072 , "compaction" : { "mode" : "safeguard" , "reserveTokensFloor" : 24000 , "identifierPolicy" : "strict" , "memoryFlush" : { "enabled" : true , "softThresholdTokens" : 6000 } } } } , "session" : { "scope" : "per-sender" , "reset" : { "mode" : "idle" , "idleMinutes" : 30 } , "maintenance" : { "mode" : "enforce" , "pruneAfter" : "7d" , "maxEntries" : 120 } } , "channels" : { "telegram" : { "enabled" : true , "historyLimit" : 30 , "accounts" : { ... } } } }
关键配置说明
配置项
值
作用
agents.defaults.contextTokens131072
多档模型共存时更稳,切回 moonshot-v1-128k 也不容易超限
agents.defaults.compaction.modesafeguard
启用保护模式,预留安全空间
session.maintenance.modeenforce
强制清理 7 天前的旧会话
session.maintenance.maxEntries120
最多保留 120 个会话
channels.telegram.historyLimit30
每次请求最多带 30 条历史
多 Bot 配置注意 上面的 historyLimit 和 session 配置放在 channels.telegram 级别,会对所有 4 个 Bot 统一生效。如果需要不同 Bot 不同策略,可以在每个 account 下单独设置 historyLimit。
多模型切换补充说明 后来我又把 step/step-3.5-flash 接进来了。这里最重要的经验是:别为了切模型去改全局默认模型,直接用 /model ... 切当前会话就够了。
原因很简单:
改全局会影响别的 Bot 和别的会话
还可能把 cron 定时任务一起带偏
当前会话切换则只影响自己这一条对话链
我现在的实际用法:
1 2 3 4 /model step /model bailian/kimi-k2.5 /model kimi/moonshot-v1-128k /model status
其中:
bailian <-> step 风险最低切到 moonshot-v1-128k 时,最容易触发短期上下文压缩
但长期记忆文件不会丢
修复后的效果
响应时间从 5 分钟+ 降至 3-20 秒
会话文件大小控制在 10KB 以内
服务连续运行 14 小时+ 无卡死
补充坑位:HEARTBEAT 抢占主会话(第19坑) 后来我又遇到过一次比 compaction 更隐蔽的问题:Telegram 能收到消息,但主 Bot 要么完全不回,要么要等很久才回。
现象
给 @GameHuOpenclaw_bot 发消息,长时间没有任何回复
日志能看到消息进入 lane=session:agent:main:main
但执行结束后没有正常的 sendMessage
重启后可能短暂恢复,过一阵又复发
真实根因 这次不是 Telegram 渠道挂了,也不是容器死了,而是 HEARTBEAT.md 的主动任务把 main 主会话占掉了
排查时我在 sessions.json 里发现,agent:main:main 这条映射的 origin.provider 已经不是 Telegram,而是 heartbeat。结果就是:
你的正常聊天消息仍然会进入 main
但 main 会话上下文已经被 heartbeat 任务污染
最终表现成“不回复”或“回复极慢”
为什么会发生 这里有个很容易误解的点:HEARTBEAT.md 很有用,但它不是核心运行时依赖 。OpenClaw 的 heartbeat 机制本身会启动,但如果你把 HEARTBEAT.md 写成“主动检查 git、主动提醒发博客、主动输出长段内容”的详细任务单,它就可能在重启、升级尝试或异常恢复后占用 main session。
我这次现场看到的情况是:
启动日志显示 update available (latest): v2026.3.7 (current v2026.2.27)
说明当时服务器实际跑的仍然是 v2026.2.27
也就是说,之前那次“升级”并没有真正成功
但升级尝试或相关重启之后,main 会话映射被 heartbeat 改写了
所以这次故障更准确地说,是升级尝试触发重启后,暴露了 heartbeat 抢占主会话的问题 ,而不是“新版本本身有 bug”。
如何判断是不是这个问题 如果你遇到“消息进来了但 Bot 不回”,重点看两处:
docker compose logs -f openclaw-gateway~/.openclaw/agents/main/sessions/sessions.json
如果日志里反复出现主会话执行,但没有正常发消息,同时 sessions.json 里 agent:main:main.origin.provider = heartbeat,基本就能确定是这个坑。
我最终采用的修复方式
先备份 sessions.json 和当前 session 文件
删除被污染的 agent:main:main 映射
重启 openclaw-gateway
把原来的激进版 HEARTBEAT.md 改成低风险版
低风险版的原则是:
默认只返回 HEARTBEAT_OK
只做静默的记忆维护
不主动发博客提醒
不做 git 巡检
不输出聊天式长文本
最稳的实践建议 如果你的 main bot 是日常高频对话入口,我现在的建议很明确:
HEARTBEAT.md 可以保留但只保留静默记忆维护 能力
主动提醒类任务放到 cron 或单独 bot
不要再把“像助手一样主动找你说话”的逻辑写进主工作区 heartbeat
这样既能保留记忆整理能力,又不会再次把主聊天打挂。
顺手补一句:如何确认升级到底成没成功 不要只看自己执行过 git pull 或 docker compose restart,要以启动日志里的版本号 为准。
如果日志仍然显示:
1 update available (latest): v2026.3.7 (current v2026.2.27)
那结论很简单:你还在跑旧版本,升级并没有真正完成。
实际使用体验 部署完成后,通过 Telegram 与 Bot 对话:
修复前(问题阶段)
响应速度:最初很快,2 天后变成 5 分钟+
稳定性:运行 2 天后完全卡死
原因:compaction 机制被大会话文件阻塞
修复后(当前状态)
响应速度:3-20 秒 ,正常可用
稳定性:连续运行 14 小时+ 无故障
内存占用:约 800MB-1.2GB
功能:文件操作、Shell 命令、网页浏览全部正常
关键优化点 配置 contextTokens、historyLimit 和 session.maintenance 后,OpenClaw 从”两天必挂”变成”长期稳定运行”。这是生产环境部署的必选项 ,不是可选项。
📷 Telegram 实际对话效果 :
安全建议
永远不要 将 openclaw.json 提交到 Git配置文件权限 :最小权限原则,但必须保证容器运行用户可读Web UI 访问 :仅通过 SSH 隧道,不要暴露在公网Telegram 白名单 :严格控制 allowFrom 列表定期更新 :关注 OpenClaw 安全公告
参考资源