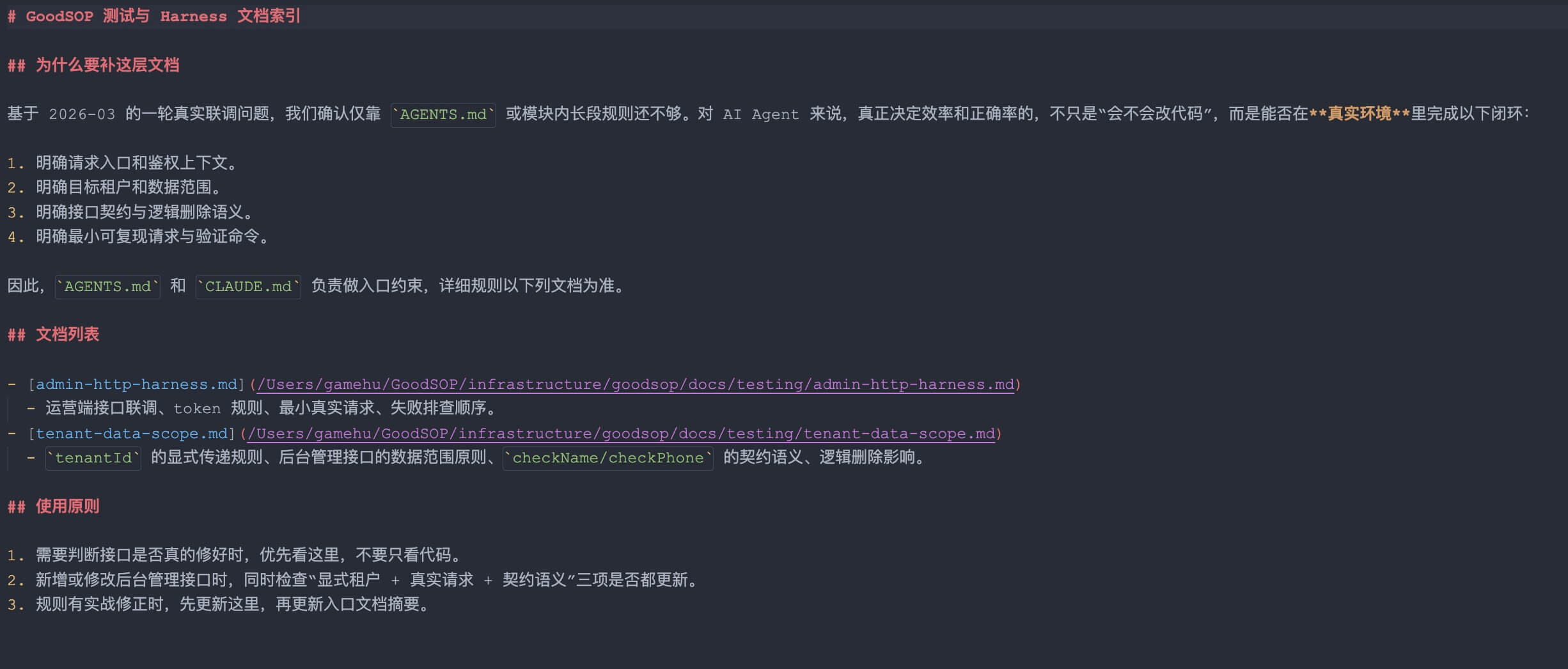
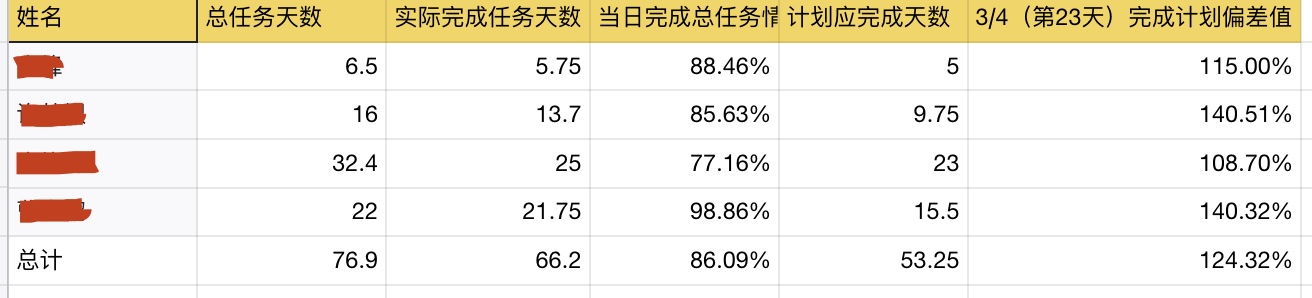
Agentic 入门:让 AI 不再一把梭,而是像人一样反复干活
最近产品里想要集成业务 Agent,真动手之前我想先把底层逻辑搞清楚,但是深入了解 agent 之前我看到了:Agentic。
它跟 Agent 不是一回事。Agent 是具体的东西,比如一个能自主干活的 AI 助手;Agentic 是一种工作方式——让 AI 能规划、执行、反思、修正,在循环里反复迭代,而不是一问一答就结束。搞懂 Agentic,才知道 Agent 该怎么搭。
说白了,Agentic 不是让 AI 更会说话,而是让 AI 更像一个会反复干活的人。
这篇是我自己的学习整理,不聊实现细节,就想先把这件事用人话讲透。
一、先想明白,我们平时到底是怎么用 AI 的
吴恩达先生以前讲过一个很形象的比喻[^1]。
他说我们现在大部分人用大模型,其实还是 Zero-shot(就是不给任何示例、不做任何拆解,直接让它一把回答)模式。你扔一个 prompt 进去,模型从第一句一路吐到最后一句,中途没有停顿,没有修改,也没有回头看一眼自己写得对不对。
这件事像什么?
像你让一个人从头到尾写一篇文章,但中途不准按退格键。
你想想,这活儿正常人都干不好,更别说我们还指望 AI 一把出神作。
这也是为什么,我现在回头看,会觉得很多时候不是 AI 本身忽强忽弱,而是我们给它的工作方式,本来就有点反人类。
不是它不能干,而是你要求它一次性把所有事情都想对、写对、做对。
但真实世界里的高手不是这么干活的。
不管是写文章、做方案、查资料,还是写代码,正常流程基本都是:
- 先想一下目标是什么
- 拆几个步骤出来
- 缺信息就去查
- 先搞一个初稿
- 回头检查漏洞
- 发现问题再改一轮
这套动作,我们人类觉得理所当然;一到 AI 身上,很多人反而想跳过。
所以我现在理解的 Agentic,本质上就是把这套”人类本来就会的迭代过程”,重新装回 AI 的工作流里。
用一张图来看,差别其实一目了然:

左边就是我们现在大部分人用 AI 的方式:一问一答,结束。
右边是 Agentic 的方式:它会自己转圈,直到结果靠谱为止。
二、Agentic 到底是什么?这是我目前最顺的一句解释
如果非要让我先给自己留一句最顺口的人话解释,我会这么说:
Agentic 不是让 AI 更聪明,而是让 AI 不再只回答一次。
它会在一个循环里反复工作。
比如你让它写一份研究报告,它不是上来就闷头输出 3000 字,而是可能先做这些事:
- 先列提纲,确认应该从哪几个角度展开
- 判断哪些部分信息不够,需要联网搜索或者调资料
- 先写一个版本
- 再自己检查这一版有没有逻辑漏洞、重复废话或者证据不足
- 然后按发现的问题继续改
你看,这不就是一个稍微靠谱点的人在做事的样子吗?
这里最关键的,不是”会不会调用工具”,也不是”会不会写代码”,而是它终于不再被限制在”一次生成、不可回头”的模式里了。
这件事带来的提升,其实很夸张。
吴恩达先生他们测过一组数据,挺有意思的:

GPT-3.5 裸跑代码题只有 48% 正确率,但套上 Agentic 循环以后,直接拉到 95%。比 GPT-4 裸跑的 67% 还高一大截。(数据来自吴恩达 2024 年在 Sequoia AI Ascent 的演讲 Agentic Design Patterns[^1])
我觉得这组数字最值得咂摸的地方,不是某个模型赢了,而是它说明了一件事:
工作流设计,在很多场景下,已经开始比”模型单次裸跑能力”更重要了。
以前大家拼谁的 prompt 写得玄。
现在越来越像在拼,谁更懂得给 AI 安排一个像样的工作流程。
三、我先把 Agentic 拆成四个最核心的招式
吴恩达先生后来把 Agentic 总结成四种常见设计模式[^1]。我自己的感受是,这四个词看起来有点学术,但翻译成人话之后,反而会一下子清楚很多。
先上一张全景图,让你对这四个模式的关系有个整体感觉:
graph TB
MA[多智能体协作
把任务分给不同角色] --> PL[规划
拆任务、定顺序]
PL --> EX[执行 + 工具使用
干活、调工具]
EX --> RF[反思
回头检查、修正]
RF -->|发现问题| PL
RF -->|通过| OUT[输出结果]
style MA fill:#e6f3ff
style PL fill:#fff3e6
style EX fill:#e6ffe6
style RF fill:#ffe6e6
简单说就是:多个角色分工(多智能体) → 每个角色先想清楚再动手(规划) → 该查就查、该调就调(工具使用) → 做完回头看一遍(反思) → 不行就再来一轮。

1. 反思(Reflection)
一句话类比:写完作文自己通读一遍,删掉废话、补上漏洞。
就是让 AI 不要交卷就跑,而是看一眼自己刚刚写了什么。
有没有逻辑不通的地方?
有没有明显没回答到题?
有没有一堆正确但没用的废话?
这一步特别像我们自己写完文章后,隔两分钟再回来看,突然发现:
“这段说了等于没说。”
“这个论点站不住。”
“这里应该删,不然啰嗦。”
很多看起来”更聪明”的 AI 应用,往往不是第一次就答得特别神,而是多了一轮自我审稿。
2. 工具使用(Tool Use)
一句话类比:查字典、翻参考书,而不是全靠记忆硬撑。
AI 靠自己脑补,肯定有上限。
所以你得允许它出门干活。
比如:
- 去搜资料
- 读文件
- 跑代码
- 查数据库
- 调 API
- 调用外部系统
工具这件事,本质上是在补模型的”手脚”。
只有脑子,没有手脚,它很多事永远只能停留在嘴上。
3. 规划(Planning)

一句话类比:做菜之前先看一遍菜谱,别上来就开火。
规划说白了就是,别一股脑往前冲,先想一下顺序。
面对复杂任务,先拆,再干,效率会高很多。比如:
- 先定目标
- 再拆子任务
- 然后决定哪些任务要查资料,哪些任务可以直接写
- 最后再汇总
人一旦不规划,容易瞎忙。
AI 一旦不规划,容易一本正经地跑偏。
4. 多智能体协作(Multi-agent Collaboration)
一句话类比:一个人拍电影不如分工——导演、编剧、摄影各管各的。
这个词听起来很高级,实际你可以把它理解成”别让一个 AI 同时扮演所有角色”。
比如一个负责搜集资料,一个负责写初稿,一个负责挑刺,一个负责做最终汇总。
甚至它们之间还可以互相辩论。
这套思路的价值,不在于搞得多复杂,而在于:
不同角色的关注点本来就不一样,拆开之后,结果往往比一个 AI 一把梭更稳。
四、从会跑到跑得稳,还差这两样东西:Harness 和 Traces
上面四个招式看起来挺简单的对吧?但一旦真让 AI 跑起来,你马上会碰到两个问题:
- 它跑偏了你怎么兜住?
- 它跑偏了你怎么知道?
第一个问题,对应的是 Harness;第二个问题,对应的是 Traces。
Harness:给 AI 装上安全带和工具腰带
如果我只把 Agentic 理解成”让 AI 多跑几轮”,那其实只理解了一半。
LangChain 的 Harrison Chase 提过一个我很认同的点:今天很多 Agentic 系统之所以变强,不只是因为模型本身更好了,而是因为我们给它加了一套越来越完整的”外围设施”。
他管这个叫 Harness。说白了,就是你在让 AI 干活之前,先给它搭好的一整套工作台——什么工具能用、什么文件能动、上下文怎么喂、出了问题怎么回滚。
举个具体的例子:你让 AI 帮你写一段代码。如果是裸跑,它只能凭记忆硬编。但如果有了 Harness,它可以先读你项目里的现有代码(文件系统权限),记住你之前说过的偏好(记忆机制),按步骤拆解任务(规划能力),跑完代码自动测试(验证机制),测试没过就自动回退(回滚机制)。
这时候你就能理解,为什么现在很多团队开始讲 Context Engineering(上下文工程),而不只是讲 Prompt Engineering 了。
打个比方:如果 Prompt 是你跟 AI 说的那句话,那 Context Engineering 就是你在它开口之前,帮它把该看的资料、该知道的规则、该用的工具全部摆到桌面上。
这俩压根不是一个量级的事。
以前大家总想找一句神 prompt 包打天下。
现在越来越像搭一个工作台,把 AI 放进去之后,它每一步都有人给它递对工具、递对材料、递对约束。
Agentic 拼到后面,拼的不是一句提示词写得多花,而是谁更会给 AI 配环境、配反馈、配护栏。
Traces:给 AI 装上飞行记录仪
好,Harness 解决了”怎么兜住”。但还有个问题:AI 跑偏了,你怎么知道它是在哪一步开始偏的?
传统软件有个好处——代码基本就是规则本身,程序为什么这么跑,你顺着代码就能看明白。
但 Agentic 不一样。它不是一条固定路径跑到底,而是在循环里不断判断、选择、调用工具、修正方向。你第 14 步看到它翻车的时候,真正的问题很可能出在第 3 步,甚至第 1 步。
这时候最有价值的东西就不是”它最终输出了什么”,而是它每一步的操作日志——每一步看到了什么上下文、为什么做出这个判断、调了哪些工具、工具返回了什么、它是基于什么决定继续还是回退。
这些记录,就是 Traces(追踪日志)。
它特别像什么?像飞行记录仪。
平时你可能不看,但一旦出事,没有它你基本就是瞎猜。
所以我现在会提醒自己,未来如果真要在业务里落地 Agentic,不能只盯着”能不能跑通”。没有 trace 的系统,很多时候只是看起来能跑,一出问题你根本没法定位。
五、对我这种准备落业务的人来说,更现实的姿势不是全自动,而是”人类在环”

上图展示的是一个理想的自主智能体循环:任务执行 → 任务创建 → 优先级排序 → 继续执行,理论上可以无限循环直到目标达成。
但看到这里,我自己先记一个结论:
小白入门 Agentic,千万别一上来就追求 100% 自动驾驶。
这事听起来很性感,做起来经常很危险。
因为长链路任务一旦完全放飞,AI 很容易在你没注意的时候,往一个看似合理、其实已经偏掉的方向一路狂奔。
所以比”全自动”更现实的做法,是先把它当成一个很强的起草机、陪练和执行器。
比如:
- 帮你先起一个方案初稿
- 帮你做一版调研汇总
- 帮你把一堆需求整理成结构化任务
- 帮你先生成代码骨架和测试思路
然后关键决策点交给人来审。
我很认同一种说法,叫 Keep the AI on the leash。
翻译得粗暴点,就是:别把绳子撒手。
你要给它一定的自主性,但这个自主性必须可调。
它能跑,但你随时能:
- 看见它干了什么
- 拒绝它的修改
- 编辑它的中间结果
- 在关键节点让它停下来等你确认
这就是所谓的 Human-in-the-loop(人类在关键节点把关)。
它听起来好像”不够自动化”,但对真实业务来说,这反而是更成熟的状态。
因为信任不是靠宣传建立的,是靠”我看得见、控得住、改得回”建立的。
六、如果我后面真要往业务里落,起步大概率会先套这个最小闭环
说了这么多,最后落到实操,我觉得最适合我这种还在往业务里试的人,Agentic 起步姿势就先四步:
graph LR
P[1. 规划
拆任务、定目标] --> E[2. 执行
搜资料、调工具]
E --> R[3. 自我反思
挑刺、补漏]
R --> H[4. 人类审核
关键节点拍板]
H -->|需要修正| P
H -->|通过| D[交付]
style P fill:#fff3e6
style E fill:#e6ffe6
style R fill:#ffe6e6
style H fill:#e6f3ff
1. 规划
先别急着让 AI 干活,先让它拆任务。
问清楚目标是什么,输出物是什么,哪些约束不能碰,哪些信息还缺。
2. 执行
该搜资料就搜,该读文件就读,该调工具就调。
这一步别只让它靠记忆硬编。
3. 自我反思
让它自己回头挑刺。
检查逻辑、补证据、删废话、找风险点。
4. 人类审核
关键节点必须有人拍板。
尤其是涉及代码变更、对外发布、客户沟通、业务决策的内容。
这四步看起来很朴素,但已经足够构成一个靠谱的 Agentic 最小闭环。
它真正打碎的,其实也是我自己之前对 AI 的一个幻觉:
不是”有没有一个神 prompt 能一次性解决问题”,而是”我能不能把问题组织成一个能不断修正的流程”。
这两个思路,差别非常大。
七、最后记一笔
如果我现在还把 AI 只当成一个高级搜索框,或者一个会写字的聊天机器人,那我大概率还没真正进入 Agentic 这套工作方式。
Agentic 的重点,从来不是”让 AI 更像人聊天”,而是”让 AI 更像一个可以在工作流里持续推进任务的执行者”。
它会规划,会调用工具,会回头反思,会在必要的时候把决定权交还给人。
我越来越觉得,接下来 AI 应用真正拉开差距的地方,不是大家都在拼模型参数,而是谁先把这套工作方式吃透。
毕竟现实里真正靠谱的人,也不是因为他永远第一次就做对。
而是因为他会:
- 先想清楚
- 再动手
- 做完回头看
- 发现不对就改
现在,只不过我们开始要求 AI 也这么干了。
参考与延伸阅读
[^1]: AI Agents that Work: Agentic Design Patterns - Andrew Ng, DeepLearning.AI
延伸阅读:
- LLM Powered Autonomous Agents - Lilian Weng (OpenAI)
- Intro to Large Language Models - Andrej Karpathy
- Birth of BabyAGI - Yohei Nakajima